Though doctors and drug makers tout “average” effects, many treatments deliver a smorgasbord of results—substantial benefits for some people, little benefit for many, and harm for a few. Why don’t we hear more about this variability?
Roughly a century ago, modern medicine got off to a roaring start. Pasteur discovered the bacterial origin of many diseases in 1870. Handwashing reduced deaths from surgery and childbirth. Antibiotics cured many infections. Vaccines wiped out polio, smallpox and chickenpox. Starting in the 1920s, insulin significantly prolonged some lives.
Since then, though, momentum gradually has slowed. Humans are vastly complex biological systems. We’ve discovered that, for chronic conditions like Parkinson’s, arthritis, Alzheimer’s, IBS, migraines and psoriasis, the effects of a given treatment vary depending on the patient. As one analysis in 2011 put it, “the development of medical interventions that work ubiquitously (or under most circumstances) for the majority of common chronic conditions is exceptionally difficult and all too often has proven fruitless.”
Researchers call a treatment’s variable effectiveness per individual its “heterogeneous treatment effect,” or HTE.
Though HTE is what’s meaningful for most patients— nobody is actually average, right?—it’s usually unmentioned in publicity for treatments.
This is because, as Richard L Kravitz, Naihua Duan, and Joel Braslow explained in a 2004 paper, treatment effect averages are the “primary focus on clinical studies in recent decades.” The average effect is what researchers look for, what the FDA approves, what drug companies promote, what doctors base prescriptions on, and what patients expect.
But, as the 2004 paper noted, the modest average effects everyone focuses on may, in fact, mask “a mixture of substantial benefits for some, little benefit for many, and harm for a few.”
There’s a second error that results from focusing on a drug study’s reported average effects, they argued. Heterogeneity “may be dramatically underestimated” because “by convenience, randomized control trial are characterized by narrow inclusion criteria and recruitment.”
In fact, “nonrepresentativeness is probably the rule rather than the exception.” Put simply, the people in a drug study often don’t reflect a population’s full diversity of race, sex or health conditions.
Kravitz, Duan, and Braslow explained that though the generalizability of a large drug trials is often relatively weak, average findings are often quickly distilled into treatment guidelines, and these, in turn, can too easily creep into rigid treatment standards. Harm can result. For example, a drug trial for a diuretic called spironolactone seemed to show a 35% benefit for the average patient, but when included in treatment standards resulted in a four-fold increase in hospitalizations and no reduction in all-cause mortality. Significant groups had been underrepresented in the original trial.
Attention to HTE probably won’t change any time soon. Unfortunately, “the pharmaceutical industry currently has little direct incentive to collect data on risk, responsiveness, and vulnerability that would better inform individual treatment decisions,” according to Kravitz, Duan, and Braslow. In fact, mass market economics incentivize one-size-fits all treatments, since doctors prescribing based on “average” results create far larger markets for drug makers.
Most people’s tests of potential treatments for chronic conditions involve haphazard cycling through doses and brands, spotty symptom diaries, and no statistical analysis of results. This lack of rigor introduces numerous cognitive biases.
When there’s no one obvious best treatment for a chronic condition, humans conduct informal experiments, observing symptoms as they move through a list of treatments until one treatment seems to be effective. Doctors refer to this strategy as trials of therapy; detractors call it trial and error.
The handbook Design and Implementation of N-of-1 Trials: A User’s Guide calls this casual approach “haphazard,” noting that “it is easy for both patient and clinician to be misled about the true effects of a particular therapy.” Other researchers call it “hardly personalized, precise, or data-driven.”
Research into human decision-making shows that an unstructured approach to treatment testing has numerous pitfalls.
People often see patterns in random events.
“We’re emotional creatures that look for signals in a sea of mostly noise,” notes medical podcaster Dr. Peter Attia. “We like to see things as we wish them to be and we sometimes consciously or unconsciously act in a manner to coax those things to our wishes. … Without a framework, in this case, the scientific method, we’re far too likely to see what we want to see rather than the alternative.”
Picking a treatment using flawed, biased or incomplete data can result in under-optimized choices or, longer term, treatment churning.
Numerous cognitive biases and statistical errors affect unstructured treatment experiments. They include:
recency bias (how I feel today while visiting the doctor is more vivid than how I felt last week)
placebo/nocebo effects (positive or negative effects may arise from psychic rather than biological factors)
sunk cost effect (I stick with a bad treatment because I’ve already invested significant time/emotion in the treatment)
clustering illusion (I attribute significance to small clusters or trends in datasets that are, in fact, only random)
physician pleasing (seeking the approval of a health care provider, I may over-report positive effects)
inconsistent standards (I use varying metrics to evaluate treatments’ effects, making a systematic comparison impossible)
rushed conformity (if rushed to give feedback, I default to an answer that’s socially desirable)
granularity bias (I can’t see small differences hidden in large data sets)
natural progression (my condition may organically increase or diminish, making the last medication tested seem more — or less — effective)
incomplete sampling (I don’t gather enough data for a statistically valid conclusion — perhaps only reporting how I’m feeling the day I visit the doctor)
You can see how some these biases play out in a typical clinical interaction based on casual experimentation, as portrayed in the N-of-1 User’s Guide:
Take for example Mr. J, who presents to Dr. Alveolus with a nagging dry cough of 2 months duration that is worse at night. After ruling out drug effects and infection, Dr. Alveolus posits perennial (vasomotor) rhinitis with postnasal drip as the cause of Mr. J’s cough and prescribes diphenhydramine 25 mg each night. The patient returns in a week and notes that he’s a little better, but the “cough is still there.” Dr. Alveolus increases the diphenhydramine dose to 50 mg, but the patient retreats to the lower dose after 3 days because of intolerable morning drowsiness with the higher dose. He returns complaining of the same symptoms 2 weeks later; the doctor prescribes cetirizine 10 mg (a nonsedating antihistamine). Mr. J fills the prescription but doesn’t return for followup until 6 months later because he feels better. “How did the second pill I prescribed work out for you,” Dr. Alveolus asks. “I think it helped,” Mr. J replies, “but after a while the cough seemed to get better so I stopped taking it. Now it’s worse again, and I need a refill.”
A systematic experimental protocol helps avoid these biases. A rigorous experiment includes:
at least 30 data points per treatment to achieve statistical significance
consistent metrics for measuring symptoms
daily symptom reports (ideal)
standard length treatment blocks, randomized
blinding (ideal)
a statistical analysis of logs at the experiment’s conclusion
If you’re interested in this approach, WhichWorksBest’s online software makes systematic personal experiments simple and affordable. For more background, read this information about single person (n-of-1) experiments, or chat with our GuideBot at the bottom of the page!
In the spring of 2019, we had been talking for nearly a year about building a software toolkit to help automate what many people already do informally—track symptoms and statistically evaluate the effects of various treatments. As the idea started to jell, we started casting about for names for the toolkit.
Though there are a variety of scientific names for the methods that the WWB toolkit borrows from— single person trial, n-of-1 trial— none of them inspired any enthusiasm.
One day, headed to the car for a brief vacation, I realized I’d forgotten my blood thinner medications. (I had a pulmonary embolism last fall.) Walking out of my home holding two bottles of best selling blood thinners — Xarelto and Elequis — one in each hand, I was thinking about the wooziness that sometimes seemed to occur while I was on the blood thinners.
I weighed both bottles and asked myself out loud, “which works best?”
I knew, from reading and conversations, that this exact question is incredibly common for people struggling to find the right solution—behavior, medicine, supplements—for chronic health conditions. Luckily, the domain name was available!
WhichWorksBest is a creation of Pressflex LLC, which has been around since 1998. The name WhichWorksBest? ties into the fairly literal, “just the facts” naming conventions that Pressflex has used for other ventures.
For example, Pressflex was founded to help newspapers and magazines get online flexibly and affordably. Blogads, which we launched in 2002, was an automated service to help bloggers sell ads. Pullquote, launched in 2011, helps people store and share interesting quotes. AdBiblio, launched in 2014, helps book publishers advertise online. Racery, also launched in 2014, helps companies and charities build and host virtual races.
One remaining puzzle. Very few companies — or zero? — have a question mark in their logo. If WhichWorksBest? ever ends up in a headline, this may confuse readers. But the questionmark also conveys the confusion and questioning that is at the heart of WhichWorksBest?
For one thing, the amount of melatonin the body produces is miniscule compared with commercial dosages. For another, there’s strong evidence that morning exposure to sunlight leads to a melatonin spike the same evening.
Here are some links that will help you think about how to structure a self-experiment with melatonin.
The literature on treatment blocks says broadly that blocks may be shorter for faster acting treatments (a one day treatment might be appropriate for pain and aspirin) and longer for treatments that have a slow, cumulative effect.
But digging into the literature for both RTCs and n-of-1 experiments, you find a wide variety of treatment block durations for the same treatments. In many cases, the durations are justified only by referencing previous experiments that have used a particular duration.
Industrial medicine views random control trials (RCTs) as the gold standard for determining the efficacy of medications. The thinking goes: blinding, controls/placebos and regular reporting produce objectively reliable, generalizable results.
Yet critics argue that RCTs, at least the ones that clinicians habitually read in the reprints of medical journal articles shared by drug company reps, are deeply flawed.
Richard Smith, longtime editor of the BMJ, argued that “Medical Journals Are an Extension of the Marketing Arm of Pharmaceutical Companies.”
Up to 75% of published RTC studies are funded by manufacturers, and (surprise!) most studies that aren’t positive for the manufacturer never get published. This “dead pool” is estimated to be roughly half of all studies. (Source.)
But even in studies affirming a medication’s efficacy often appear to have been rigged. Smith compiled this list of strategies drug companies use to rig RTCs:
* Conduct a trial of your drug against a treatment known to be inferior.
* Trial your drugs against too low a dose of a competitor drug.
* Conduct a trial of your drug against too high a dose of a competitor drug (making your drug seem less toxic).
* Conduct trials that are too small to show differences from competitor drugs.
* Use multiple end points in the trial and select for publication those that give favourable results.
* Do multicentre trials and select for publication results from centres that are favourable.
* Conduct subgroup analyses and select for publication those that are favourable.
* Present results that are most likely to impress – for example, reduction in relative rather than absolute risk.
A new study of recently introduced drugs in Germany finds that many of the drugs confer no appreciable benefit relative to existing drugs:
Between 2011 and 2017, IQWiG assessed 216 drugs entering the German market following regulatory approval, they explain. Almost all of these drugs were approved by the European Medicines Agency for use throughout Europe.
Yet only 54 (25%) were judged to have a considerable or major added benefit. In 35 (16%), the added benefit was either minor or could not be quantified. And for 125 drugs (58%), the available evidence did not prove an added benefit over standard care in the approved patient population.
The situation is particularly shocking in some specialties, they add. For example, in psychiatry/neurology and diabetes, added benefit was shown in just 6% (1/18) and 17% (4/24) of assessments, respectively.
Medicine beyond the clinic: wearables + genomics + networked patients + AI
Pulling together everything that’s above, we can predict the location and shape — if not the exact form — of what what’s ahead in the next 20 years.
Obviously, large chunks of the industry of medicine will remain intact. Health care specialists and institutions focused on obstetrics, orthopedics, and trauma will stay strong. Some specialties will morph, adopting these tools and remaining as gatekeepers in the dispensation of health advice and molecules.
But with healthcare today making up 18% of US GDP, it’s hard to imagine how we can spend more. (Though is worth noting that a journalist — one Michael Crichton — made the same observation in 1970 in The Atlantic… when healthcare constituted 6.2% of GDP.)
As with all disruptive innovation, change will occur at the edges, where consumers will access cheaper, weaker products/services to meet needs that are currently unmet (and often unimagined) by the behemoth.
The fault line running between the old and new paradigms can sketched using these rough dyads:
Data sourcing: recruited by doctors, researchers, funded by grants from NIH, PHARMA >> recruited via OpenHumans, Patientslikeme, Reddit, Kickstarter, GoFundMe, Clusterbusters, Crohns.org, eHealthme, 23andme
Diagnostics generated by: professional training/touch/intuition/book-size rubrics >> big data/AI
Data timing: crisis-triggered >> real-time/365 data collection
Jurisdictions: constrained by local laws >> unregulated or transnational legal rules or jurisdiction shopping
Dosing: one-size-fits all based on drug trials with 100s of participants >> dosing based on analysis of outcomes for millions of users differentiated by age, sex, race and other conditions
Data quality: corrupted by multivariate confounding >> multivariates teased apart
Data tabs: Limited to broad demographics >> analysis factoring in variables like personal genetics and environmental inputs (sun, exercise, food)
Discovery of polypharma: small, trial and error investigation, ad hoc awareness of polypharma (pros or cons) >> massive, objective datasets mined for multivariate drug-drug interactions and health outcomes
Tracking of iatrogenic harm: maker/prescriber-biased reports of >> analysis of outcomes for millions of users plus crowd sourced
Mediators: GPs and specialists >> nurses and PAs
Data access: ad hoc, via doctor or library searches >> subscription-based or Google sourced
Timeline: decades >> years
In theory, there are dozens of business ideas sprouting along the fault line between each of those dyads. We’ll see.
A final thought: China seems an obvious candidate to lap the US on healthcare. Mandatory, population-wide social behavior “grading” is already in place. Healthcare is, notionally, universal. And phone producers like Huawei are aligned, if not in bed, with the government.
Simpler, cheaper and serving non-consumers, disruption creeps in from the edges
To get a glimpse of what’s ahead for health care — both the medical industry and the consumer services that will grow up, around and below that industry — there’s no better guide than the theory of innovation and industrial life cycles first described in 1995 by Clayton Christensen, a professor at Harvard Business School.
Here’s my summary disruptive innovation, based on multiple readings Christensen and his acolytes.
First, the scene is set.
chasing profits, a mature industry focuses on its most lucrative customers, building what Christensen calls “sustaining innovations”
coddling those high-end customers, the mature industry often relies on an expensive sales/marketing infrastructure (salespeople, showrooms, magazine ads, conference sponsorships, consultant’s fees)
eventually, the goods or services on offer exceed the needs and price point of many customers — some know they’d settle for a lower quality product/service, particularly if it’s significantly cheaper and serves some previously unserved need
frustrated customers who can’t afford these over-engineered solutions start to hack solutions themselves using weaker, cheaper tools
a non-incumbent producer, often from an adjacent industry, starts selling a low-end product, often through a new, cheaper sales/marketing channel
the non-incumbent market entrant steadily innovates on both the product and the business model
Now the big action comes… disruption!
lower prices unlock new demand from different, previously unforeseen customers, and an entirely new type of buyer emerges that’s far bigger than the original “elite” customer group.
new features are created to serve that new customer group, providing benefits that were unimaginable or unachievable in the prior industrial matrix. (Lots of examples here.)
the new product eventually improves enough on the original metric of success that it eventually exceeding the capacities of what’s needed by the original high-end customers.
they desert. The industrial incumbents that have served the elite faithfully collapse.
Disruption complete.
(If you’re a biz geek, its also worth reviewing the first two minutes of this interview with Christensen.)
Arguably, we’ve already seen a blueprint for what’s ahead for the medical industry in the last 20 years as technology has, time and again, blown up previously dominant information processing incumbents. (And what is the medical industry, if not an information processing incumbent?)
Some examples of information processing incumbents that were rock solid 20 years ago but have subsequently been have been disrupted:
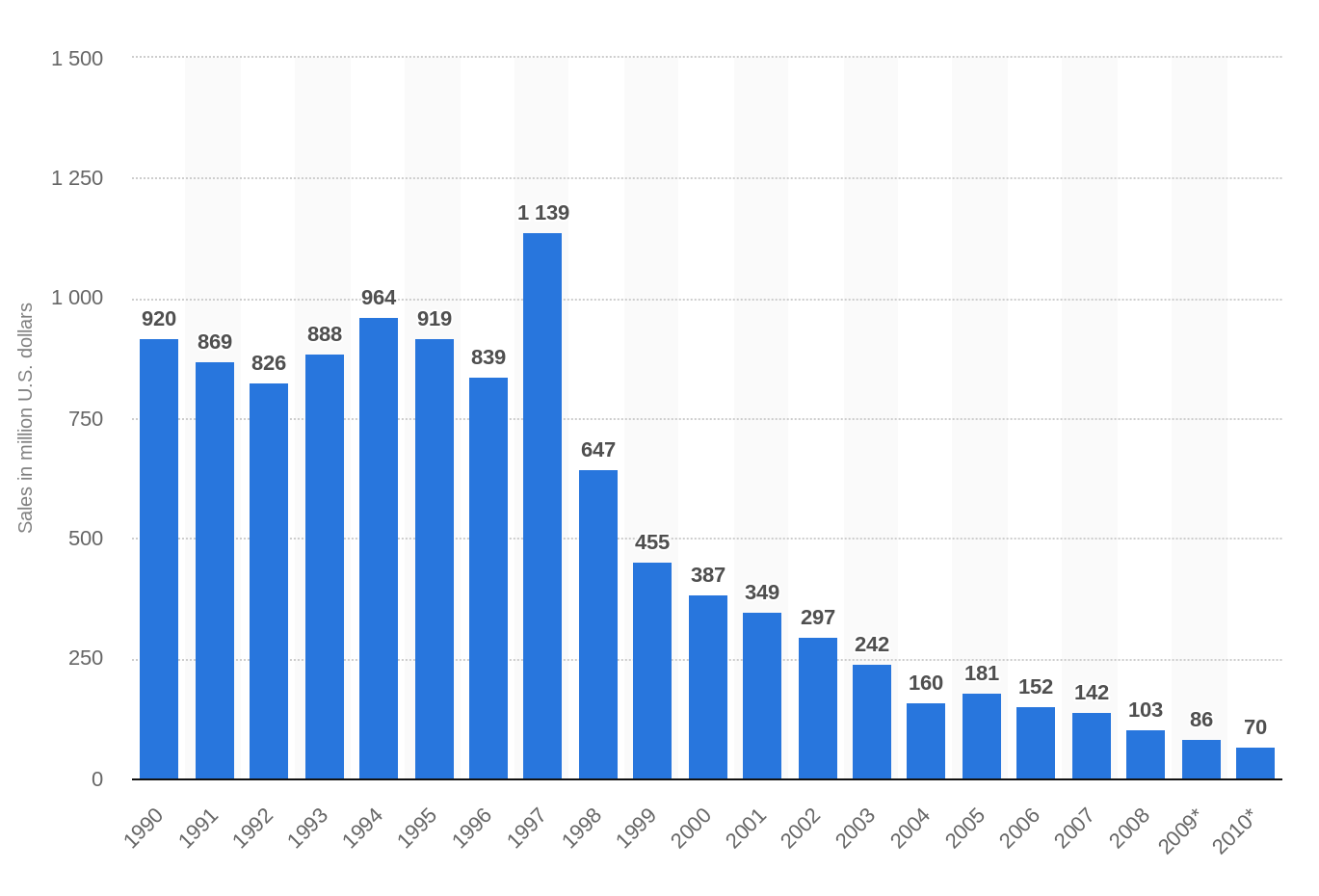
Annual sales of the Encyclopedia Britannica dropped from 120,000 in 1993 to below 10,000 before print sales ceased entirely in 2012.
The newspaper industry, which once employed 400,000 people in the US, has been eviscerate as consumers swap or create news on their own on Facebook.
More recently, movie moguls have realized they can’t compete with the breadth and depth of Netflix, much less a witch’s brew of Fortnite, Pornhub and Joe Rogan’s Youtube channel.
(But obviously that’s not exactly going to happen. Medicine is far more than a vast information processing machine — it’s a nurse’s careful touch, an ER doctor’s probing questions, an obstetrician’s forceps, an orthopedic surgeon’s meticulous drilling.)
In the medical industry, all these forces will work together to create massive and unforeseeable second order effects. Did anyone predict that flip phones would eventually lead to the Apple and Google App stores, with uncountable apps and generating $100 billion in annual revenue?
(It’s worth noting that, Christensen’s 2010 book applying his own theory of disruption to medicine, The Innovator’s Prescription, was tangled and uncompelling. Worse, it basically punted on the dream that the industry of medicine would be disrupted. Christensen concluded that though specialities like radiology might be disrupted, and nurses might someday be empowered by technology to do the work of specialists, the overall problem of medical gridlock might only be resolved by a mix of government intervention and luck. This may be a case of bad timing. Christensen hadn’t yet glimpsed many of the forces and technologies sketched in this essay. This isn’t the first time Christensen overlooked disruptive technology right before it took off. His 2013 book Innovator’s Solution pooh poohed the value of cameras in cell phones.)
Diagnostics and treatments already lag best practices by 17 years
Given these cascading exponential changes, what might we say about the future of US healthcare, beyond the most obvious — expect the unexpected?
Let’s start with the effect of this multi-dimensional convergence of change shock waves on the existing US medical industry.
First, obviously, many innovations will be readily integrated by the industry. Exponential improvements in hardware and software will augment rather than cannibalize existing services. Some examples of improvements that will simply “bolt in” to the existing infrastructure include:
But the number of innovations that are adopted will be dwarfed by those that are wait listed and back ordered.
Part of the problem is structural. The industry is a continent-spanning Rube Goldberg machine cemented together by crazy glue. It is almost as complex as its putative subject, the human body. It’s comprised of a matrix of institution (hospitals, insurance companies, drug manufacturers, med schools, device makers, regulators), individual roles (general practitioners, nurses, physicians assistants, physical therapists, regulators, administrators, technicians, insurance coders, researchers, salespeople of all stripes, specialists) and informational sockets (pricing, practice, process, billing code, training, diagnostic procedure, testing protocol, delivery method.) Any change in one node usually requires coordinated concurrent changes spanning multiple other nodes. This complex interdependence means stasis or gridlock are its default modes.
Trying to bridge the gap between what the system permits and patients want, humans are stretched to the breaking point.
Like some virulent bacteria doubling on the agar plate, the [Electronic Medical Records] grows more gargantuan with each passing month, requiring ever more (and ever more arduous) documentation to feed the beast. …
To be sure, keeping electronic records has benefits: legibility, electronic prescriptions, centralized location of information. But the E.M.R. has become the convenient vehicle to channel every quandary in health care. New state regulation? Add a required field in the E.M.R. New insurance requirement? Add two fields. New quality-control initiative? Add six.
Medicine has devolved into a busywork-laden field that is slowly ceasing to function. Many of my colleagues believe that we’ve reached the inflection point at which we can no longer adequately care for our patients.
But shortages of skills and hours are just two of many factors constraining the medical industry’s ability — or desire — to keep up with healthcare innovation.
Doctors argue that this system’s reticence serves to protect patients from quack science. But sometimes their foot dragging grows from egotism or financial self-interest. In the late 19th century, many doctors fought the professionalization of nursing, lest the new players harm the incumbents’ livelihoods and authority. The guild’s interests haven’t changed. Just 40 years ago, pregnancy test manufacturers held off on launching home tests for fear of offending their traditional customers — doctors. Even after home tests became available in 1977, some doctors continued to resist.
…the Texas Medical Association warned that women who used a home test might neglect prenatal care. An article in [The New York Times] in 1978 quoted a doctor who said customers “have a hard time following even relatively simple instructions,” and questioned their ability to accurately administer home tests. The next year, an article in The Indiana Evening Gazette in Pennsylvania made almost the same claim: Women use the products “in a state of emotional anxiety” that prevents them from following “the simplest instructions.”
Stents are another example of the sticky status quo. Stents are apparently ineffective in all but extreme cases of heart disease, a 2011 article in the Journal of American Medical Association argued that more than 70,000 unnecessary stent implants were being performed annually in the US, despite the fact that 3% of patients experience serious complications.
For all the truly wondrous developments of modern medicine — imaging technologies that enable precision surgery, routine organ transplants, care that transforms premature infants into perfectly healthy kids, and remarkable chemotherapy treatments, to name a few — it is distressingly ordinary for patients to get treatments that research has shown are ineffective or even dangerous. Sometimes doctors simply haven’t kept up with the science. Other times doctors know the state of play perfectly well but continue to deliver these treatments because it’s profitable — or even because they’re popular and patients demand them. Some procedures are implemented based on studies that did not prove whether they really worked in the first place. Others were initially supported by evidence but then were contradicted by better evidence, and yet these procedures have remained the standards of care for years, or decades.
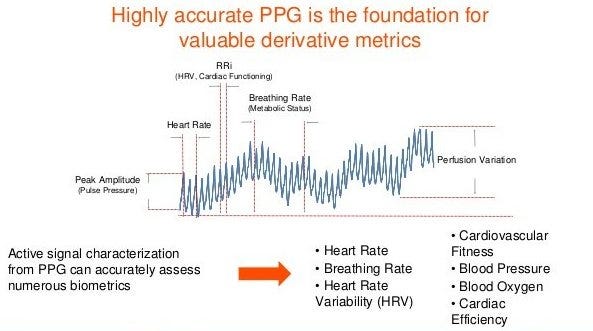
Medicine’s most iconic act, listening to your heart, offers one example of how inadequate the status quo (the stethoscope) is versus what’s already a few years behind the cutting edge (a $100 Fitbit.) Sampling a patient’s heart rate briefly once yearly, a doctor glimpses just 0.000016% of the period covered by a Fitbit, which checks and records the wearer’s heart rate every couple of seconds. That’s a black-and-white snapshot versus a movie capturing both minute-to-minute motion and longer term trends… what was your average heart rate last week or last month or last year? And it records micro-fluctuations in heart rate as the wearer breathes in and out — heart-rate-variability — a measurement that correlates strongly with both happiness and longevity.
Metrics currently generated devices with photoplethysmography (PPG). (Source: Valencell.com)
But, at present, the average doctor doesn’t ask her patient for Fitbit data because, as several docs told an NPR reporter, they wouldn’t know what to do with it. One rationalized: “I get information from watching people’s body language, tics and tone of voice. Subtleties you just can’t get from a Fitbit or some kind of health app.” (Ironically, that’s exactly how doctors responded to early thermometers.) Some doctors actively avoid seeing the data, fearing that missing a subtle clue (perhaps discernible in hindsight after a heart failure) might trigger a malpractice claim.
Summing up, the industry is overwhelmed, defensive, recalcitrant.
Even when not swamped by innovation, the medical industry requires an average of 17 years to adopt significant innovations. How long is 17 years when measured against technology life cycles? By the year 2036, when the medical industry fully adopts 2019’s state of the art in technology — say asking every patient for her/his iWatch data dump — health technology will be at least 10,000-fold more sophisticated than today. In effect, the medical industry is a pogo stick chasing a star ship.