Intro: Incremental AI assists to doctors will cascade into healthcare revolution
Five years ago, I was diagnosed with central sleep apnea. Apparently my brain sometimes forgets to remind my lungs to breath when I’m sleeping. While a diagnosis of central sleep apnea (CSA) doesn’t compare with cancer’s urgency or MS uncertainty, CSA’s short-term effects (headaches and bad dreams) and long-term implications (higher risk of neurological disorders) got my full attention.
My physician offered no cure. But recently, I spent 30 seconds searching Consensus.app, an AI tool that distills the wisdom of 200 million research articles, and learned about Diamox, a drug that is remarkably effective at reducing CSA. Though Diamox has been extensively studied, it’s largely ignored by the medical establishment, perhaps because it’s off-patent and lacks a highly motivated corporate champion.
Obviously, the press is full of stories about AI in medicine: AI is transcribing doctor’s notes from appointments, optimizing patient positioning for CT scans, analyzing millions of potential atomic structures for curative efficacy, and automating telehealth onboarding. It’s easy to forecast that AI will transform or obliterate the technology we use today to analyze and treat people, for example, as this analyst suggests, “vanquishing” pagers and fax machines over the next 25 years.
But each of those examples represent incremental rather than transformative changes. In each, AI displaces existing tech or grafts some new power onto an existing tool; each resembles taking a sail off a tall ship and replacing the lost power with an engine and screw propeller. Ships can move when the wind isn’t blowing, but the world doesn’t immediately change.
But, as with shipping, far bigger changes are ahead. Just as engine-powered ships eventually exploded the volume of global trade, spawned giant manufacturing complexes and sales channels, and gave consumers access to better, cheaper goods, accumulations of small changes wrought by AI will eventually cascade into entirely new categories of experience for health providers, medical institutions, and consumers. In hindsight, today’s medicine will look as archaic as a tall sailship.
Today, most of the emergent categories and experiences that AI will unlock are invisible. You might say they’re just glimmers in the marketplace’s eye; novel applications barely exist, consumers don’t yet know what to call the services or devices they crave, monetization models don’t exist, and the value chains and resellers that will eventually deliver the goods and services to the mass market also don’t exist. But if we look closely enough — for example at my experience with CS and Diamox — we see some visible hints of the radical changes ahead in healthcare’s fundamental structure and footprint.
Seeking a cure for CSA
As I mentioned above, recently I’ve been playing around with various AI tools that focus on medicine and healthcare. The tool that so far most impresses me is Consensus.app.
Consensus.app has digested and analyzed 200M+ academic papers and research studies in the Semantic Scholar database. From Consensus’s FAQs: “Consensus is an academic search engine, powered by AI, but grounded in scientific research. We use language models (LLMs) and purpose-built search technology (Vector search) to surface the most relevant papers. We synthesize both topic-level and paper-level insights. Everything is connected to real research papers.” The tool is available to the public, and searches are free.
That sounds very theoretical, so let’s dive into my own experience. I used Consensus to investigate a topic that strongly interests me: I suffer from central sleep apnea (CSA), which means that when I’m sleeping, my brain occasionally doesn’t remind my lungs to breathe. (Here’s the NIH on CSA.) Some days, I wake up with a headache, or I’m groggy in the middle of the day. My average blood oxygen saturation (SPO2) at night, as measured by my Fitbit, ranges between 93% and 96%, averaging 94% or 95% most nights. One other unpleasant symptom of CSA: on nights when my SPO2 average is low (which means it occasionally dips a lot lower) I sometimes startle awake out of an unhappy or angry dream. Maybe that’s my mind trying to create a story that explains its sudden oxygen-deprived state? Worse, though, sleep apnea significantly increases my risk of Alzheimers (by 28%) and Parkinsons (by 54%).
When I was diagnosed with CSA, I asked my doctor, a smart guy in his mid 40s whose site says he’s a “third generation internist,” if he recommended any medication. He shrugged and said no. (The NIH agrees, stating that all possible medications for CSA are “investigational” and “there is no approved pharmacological treatment for CSA.”) My doctor suggested I might try a CPAP machine, but noted that this technology is mostly studied for people with obstructive sleep apnea. Unfortunately, I used a CPAP for six months and a) it was a pain and b) didn’t move the needle for me.
I decided to test Dr. AI, asking Consensus: “Is there a drug that reduces central sleep apnea?” After 10 seconds, Consensus proposed three candidates, with extensive notes about their pros and cons. According to Consensus, the top candidate is acetazolamide, a drug often used by climbers to reduce altitude sickness. The drug, I learned, has been widely prescribed for glaucoma and heart disease since the 1950s.
I asked Consensus.app for more information about acetazolamide’s effects on CSA. The tool’s answer is extensive, with each point backed by supporting bullets and footnotes. Here’s a screenshot of the intro…
Each bullet is footnoted.
It happens that I had an unfilled prescription for a small quantity of acetazolamide (brand name Diamox) that I’d previously gotten in anticipation of a trip to Boulder, CO. At 5,400 feet, Boulder’s elevation doesn’t bother most people, but apparently CSA often is exacerbated by elevation. (Here’s Consensus’s take on the topic.) The Boulder trip got canceled, so based on the Consensus recommendation and a null search literature about Diamox causing any harm, I decided to start taking Diamox an hour or two each night before bed.
Since I started this experiment two weeks ago, my oxygen saturation has been consistently 96% or 97%. (Again, to jog your memory on how big an improvement this is, previously my SPO2 had gyrated between 92% and 96%, weighing in most nights at 94% or 95%.) Beyond the marked improvement in my nightly SPO2 average, I have experienced zero morning headaches, and, at night, no more jolting awake from dreams choked by agitation or confrontation. Doses that are four times higher than mine have tested safe when prescribed for at least six months. (The drug hasn’t been studied longer than that, likely because it’s off-patent and no drug company stands to reap windfall profits if acetazolamide is determined to be a miracle drug for say, I dunno, the 1-2% of US adults who have sleep apnea and are drifting towards Alzheimers.)
The disruption blueprint
Zooming way out, what might this anecdote about AI’s role in my own health journey possibly mean for the future of medicine?
It’s clear to me that AI will disrupt medicine and healthcare, not just augmenting traditional practices and institutions, but creating entirely new experiences and processes that supersede what exists today. When I say “disrupt,” I don’t just mean disturb or change. I mean utterly transform. This will happen according to a specific plot arc — disruptive innovation — we’ve seen enacted time and time again in the history of technology. In 1995, Harvard Business School professor Clay Christensen posited that a “disruptive innovation” starts life underpowered, cheap, outside traditional sales channels and serving customers whose needs aren’t met by existing solutions (or whose needs aren’t yet even articulated.) Eventually, the disruptive innovation spawns a new commercial ecosystem — new sales channels and consumer appetites — and migrates upward — in power AND the sophistication of the customer needs it serves — and obliterates incumbents.
In the history of the hard-disk-drive industry, the leaders stumbled at each point of disruptive technological change: when the diameter of disk drives shrank from the original 14 inches to 8 inches, then to 5.25 inches, and finally to 3.5 inches. Each of these new architectures initially offered the market substantially less storage capacity than the typical user in the established market required. For example, the 8-inch drive offered 20 MB when it was introduced, while the primary market for disk drives at that time-mainframes-required 200 MB on average. Not surprisingly, the leading computer manufacturers rejected the 8-inch architecture at first. As a result, their suppliers, whose mainstream products consisted of 14-inch drives with more than 200 MB of capacity, did not pursue the disruptive products aggressively. The pattern was repeated when the 5.25-inch and 3.5-inch drives emerged: established computer makers rejected the drives as inadequate, and, in turn, their disk-drive suppliers ignored them as well. But while they offered less storage capacity, the disruptive architectures created other important attributes – internal power supplies and smaller size (8-inch drives); still smaller size and low-cost stepper motors (5.25-inch drives); and ruggedness, light weight, and low-power consumption (3.5-inch drives). From the late 1970s to the mid-1980s, the availability of the three drives made possible the development of new markets for minicomputers, desktop PCs, and portahle computers, respectively. Although the smaller drives represented disruptive technological change, each was technologically straightforward. In fact, there were engineers at many leading companies who championed the new technologies and huilt working prototypes with bootlegged resources before management gave a formal go-ahead. Still, the leading companies could not move the products through their organizations and into the market in a timely way. Each time a disruptive technology emerged, between one-half and two-thirds of the estahlished manufacturers failed to introduce models employing the new architecture – in stark contrast to their timely launches of critical sustaining technologies.
To be clear, disruptive innovation isn’t just a blueprint that applies to the computer industry. Take, for example, the disruptive path of steamships to replace the prevailing transportation technology of 18th century, giant sail ships: “When steamships were introduced they were not reliable enough to travel trans-Atlantic distances, they couldn’t travel far without breaking down, and they were inclined to blow up. But steamships were able to find a niche in lake and river transport, where the distances were short, and where they had the advantage of being able to travel against the wind and on wind-still days. Once in the niche they could improve reliability until they were able to travel trans-Atlantic. Once that happened, all shipping switched to steam, and all the companies producing trans-Atlantic sailing ships went out of business; not one survived into the 20th century.” (Source.)
Maybe disruption’s avalanche begins with Consensus.ai (and peers)
With the disruptive innovation blueprint in mind, we can forsee that while AI may not replace doctors entirely — after all, they’ve got a powerful lobby and are deeply entrenched in our culture, laws, and health institutions — it will likely radically redefine what patients expect from them, starting in niches where traditional systems and practices fall short.
Unfortunately, as we all know, there’s lots of shortfall. The average doctor spends just 4 hours reading research per week, the average doctor’s knowledge is 17 years behind current research and best practices and most doctor’s visits clock in around 20 minutes. Doctors’ prescription habits are too often shaped by drug company promotions ranging from studies PHARMA finances to ads the drug makers buy in medical journals to brochures they distribute via drug reps. Laypeople’s access to best practices and medications that AI recommends will also boost demand for old, off-patent meds like acetazolamide that can play a transformative role in patients’ lives. Seriously people, if CSA and OSA might significantly boost your odds of Alzheimers and Parkinsons, why the hell aren’t doctors prescribing acetazolamide? Oh, right, no drug company will reap windfalls from the off-patent drug, and there are no drug reps pushing it. Any better reasons you can think of?
In the end, AI will disrupt healthcare just as it has other industries, not by replacing doctors outright, but by empowering patients to investigate their own solutions. This, in turn, will disrupt the value chains and marketing channels in which doctors are embedded: med schools, the FDA, EPIC, medical journals, drug company marketing infrastructure, and hospital systems. Tools like Consensus are just the beginning. They give us a glimpse of a future in which access to expert medical knowledge is democratized, forcing traditional and sometimes complacent healthcare gatekeepers to reach further, slash prices, and evolve quickly to meet consumer demand. The history of disruptive innovation — from tall sail ships to 5 1/4 inch disks — suggests the odds are heavily stacked against the incumbents.
12/23/24 Superhuman performance of a large language model on the reasoning tasks of a physician: “In conclusion, o1-preview demonstrates superhuman performance in differential diagnosis, diagnostic clinical reasoning, and management reasoning, superior in multiple domains compared to prior model generations and human physicians. Given the pace of improvement of automated systems on medical reasoning benchmarks, better and more meaningful evaluation strategies are urgently needed. Performance of LLMs on challenging diagnostic problems indicate opportunities to leverage the models to support clinicians in real-world settings. Clinical trials and workforce (re)training with integrated AI systems are needed to confirm the potential of such systems to boost clinical practice and patient outcomes.”
Tseitelman rushed to the rabbi to ask him what to do about an appendicitis attack. The rabbi prescribed a regular dose of cabbage. Miracle of miracles, within three days, Tseitelman returned to the rabbi to advise him that he had been cured. The rabbi, extremely satisfied, wrote in his notebook, “If a man comes to you with a case of appendicitis, cabbage helps.”
The next week Shapiro came to the rabbi with a case of appendicitis. The rabbi checked his notebook and promptly prescribed a diet of cabbage. Within a day, Shapiro was dead.
The rabbi again pulled out his notebook. Where it was written, “If a man comes to you with a case of appendicitis, cabbage helps,” the rabbi added, “in fifty percent of the cases.”
From: The Jokes of Oppression: the humor of the Soviet Jews
Amid the tumbling flood of gossip, duels, dinner parties, battles, clothing choices, serf-floggings and broken engagements that comprises most of Leo Tolstoy’s War and Peace sit quiet islands of wisdom about how humans’ needs knit together to form social instruments and institutions. Resting on the bedrock of human nature, these islands are as ageless as the rest of Tolstoy’s torrent is ephemeral.
One of these islands, tucked into Volume III Part 1, Section XVI, describes both the incommensurable uniqueness of many human illnesses and the self-serving psychology of care giving.
Here’s how Tolstoy describes the illness and treatment of one Natasha Rostov:
Doctors visited Natasha both singly, and in consultation, spoke a good deal of French, German, and Latin, denounced one another, prescribed the most varied medications for all the illnesses known to them; but the single thought never occurred to any of them that they could not know the illness Natasha was suffering from, as no illness that afflicts a human being can be known; for each human being has his peculiarities, and always has its own peculiar, complex illness, unknown to medical science, not an illness of the lungs, the liver, the skin, the heart, the nerves, and so on, recorded in medicine, but an illness consisting in one of the countless combinations of afflictions of these organs. This simple thought did not occur to the doctors (just as it cannot occur to a sorcerer that he cannot do sorcery), because their life activity consisted in treating patients, because that was what they were paid for, and because they had spent the best days of their lives doing it. But above all else, that thought could not occur to the doctors, because they saw that they were unquestionably useful, and indeed they were useful to all the Rostov household. They were useful not because they made the patient swallow what were for the most part harmful substances (the harm little felt, because the harmful substances were given in small quantities), but they were useful, necessary and inevitable (for the same reason that they are and always will be and that there will always be imaginary healers, fortune tellers, homeopaths, and allopaths) because they satisfied the moral need of the sick girl and the people who loved her. They satisfied that eternal human need for the hope of relief, the need for compassion and action, which a human being experiences in time of suffering. They satisfy that eternal human need—noticeable in a child in its most primitive form—to rub place that hurts.
What would Sonia, the count and countess have done, how could they have looked at the weak, wasting Natasha, without undertaking anything, if it had not been for this taking pills at specific time, warm drinks, chicken cutlets, and all the details of life prescribed by the doctors, the observance of which constituted the occupation and comfort of everyone around her? The more strict and complicated the rules, the more comforting it was for everyone. How could the count have borne the illness of his beloved daughter, if he had not known that Natasha’s illness was costing him thousands of rubles and he would not spare thousands more to be of use to her; if he had not known that if she could not get better, he would spend thousands more and take her abroad and hold consultation there; if he had no occasion to talk in detail about how Metivier and Feller had not understood the illness, but Frieze had, and Mudrov had diagnosed it still better? What would the Countess have done if she had not been able to quarrel occasionally with a sick Natasha for not fully observing the doctor’s prescriptions?
Time passes. Finally, “despite the large quantity of pills, drops, and powders she had swallowed,” Tolstoy concludes that “youth had its way,” and Natasha started to recover.
A good article in MIT Sloan Review about patient innovation mentions the rise of n-of-1 trials:
Fortunately, very low-cost approaches exist and are being developed to make it practical for patients — both individuals and groups — to carry out high-quality, ethically appropriate trials. Many of them involve a trial design called “n of 1,” in which trials are of a single patient, or “aggregated n of 1” for multiple patients.
One way to correct for the gaps the gold standard leaves in our knowledge is the “N of 1” trial, where the number of participants (N) is one instead of hundreds or thousands of volunteers. That one person works with the doctor to test a narrow hypothesis — for example, “I think drinking milk will make me feel sick. Am I right?” There are still controls. Ideally, there are still placebos. But at the end, what you get is a patient-specific, individualized answer. It’s a process shown — by controlled clinical trials, no less — to improve patient outcomes. And scientists working with these studies today, including Saeed, are almost invariably enthusiastic about N of 1’s potential.
Medicine’s history is often portrayed as a sequence of discoveries, each made by white-coated researchers working in a laboratory. In fact, though, the biggest changes in US medicine over the last 200 years were steered by forces outside of labs—specifically, by media.
How medicine’s stakeholders communicated in different eras—in formats including medicine shows, newspapers, form letters, cars, telephones, medical journals, manuals and TVs—determined what was communicated. Where information flows, medicine follows. Now social media is ushering in a new age, one of patient-generated medicine.
(Updated September 2020)
In pop histories, medicine occurs in a vacuum, its past two centuries portrayed as a self-contained timeline of rational progress. Medical history transpires in labs, clinics and operating theaters; the outside world is silent. A succession of autonomous, brilliant, persistent men (and a few women) conduct increasingly refined experiments. Theories and practices improve. Someone in a white lab coat occasionally shouts “Eureka!”
Excerpts from one timeline exemplifies this type of history:
1844 Dr. Horace Wells uses nitrous oxide as an anesthetic
1847 Ignaz Semmelweis discovers how to prevent the transmission of puerperal fever (wash hands!)
1870 Robert Koch and Louis Pasteur establish the germ theory of disease
1879 First vaccine developed for cholera
1899 Felix Hoffman develops aspirin
1922 Insulin first used to treat diabetes
1928 Sir Alexander Fleming discovers penicillin
1950 John Hopps invented the first cardiac pacemaker
1955 Jonas Salk develops the first polio vaccine
1978 First test-tube baby is born
Unfortunately, timelines of discoveries don’t account for the most important changes in medicine. No notice is taken of changes in the roles of patients, manufacturers, doctors, promoters, researchers, or of changes in what counts as medical knowledge. These changes can only be understood by examining the media through which medical knowledge and relationships have been organized and communicated.
Before turning to the history of medicine in the US, I’ll quickly survey the thinking of three academics who, writing in the second half the twentieth century, argued that revolutions in communications technology over the prior 500 years drove fundamental cultural, economic and political transformations.
Few people actually read his idea-clotted books, but most college students know how to invoke Marshall McLuhan’ aphorism “the medium is the message” when trying to spice up an essay. The most common interpretation of McLuhan’s aphorism: the tools we communicate with dictate the shape of the content we convey. Amphitheaters spawn comedies and tragedies; books cultivate linear narratives and logical exposition; 45 RPM records spin-off 3-minute tunes; TV portrays flashy, disjointed visuals. (Tech observer Clive Thompson concisely summarizes this gloss on McLuhan.)
But McLuhan’s claim stretches much further.
First, McLuhan argues that a medium isn’t just a tool for mass communication like newspapers, TV, movies, books, and radio. (Although journalists and authors often flatter themselves that McLuhan cared most about their output.) In the first paragraph of his 1964 book Understanding Media: The Extensions of Man, McLuhan defines media as “any extension of ourselves.” And his ensuing discussion of media includes telephones, rifles, sports, cities, comics, theater, clocks, roads, cars, airplanes, and money. Really, for McLuhan, any human construct that plays a role in how people relate to knowledge, the world, or (most importantly) each other, is a medium.
Second, for McLuhan, a medium does not only shape its own contents or immediate environment. Its effects are pervasive, seeping out to influence how we generally live and work. “The medium… shapes and controls the scale and form of human association and action.” We make the tool, then the tool remakes us. When the medium is an ocean, we grow gills and swim; when it’s a sky, we sprout wings and fly. In McLuhan’s metaphorical gender-fender-bender, “man becomes the sex organs of the machine world.”
According to McLuhan, “the effects of technology do not occur at the level of opinions or concepts, but alter sense ratios or patterns of perception steadily and without any resistance.” What counts as reality varies, depending on what we’re counting with.
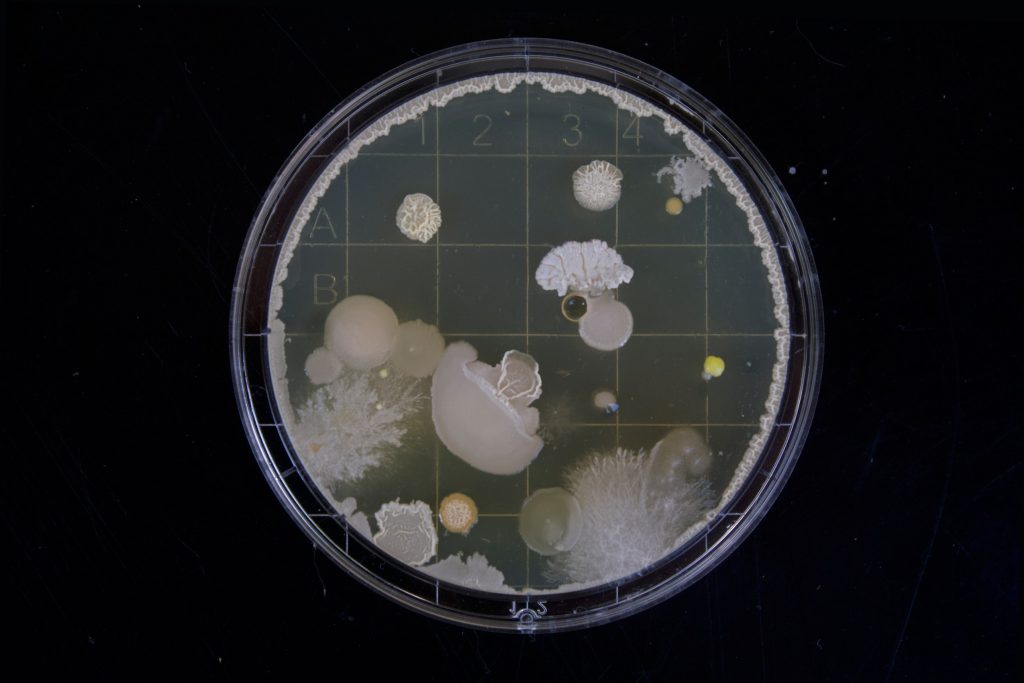
To liberate “medium” from its common identification with press and entertainment, it helps to remember the word’s meaning in a biology lab: “a substance, such as agar, in which bacteria or other microorganisms are grown for scientific purposes.” In this sense, humans are like bacteria floating in a petri dish, barely able to distinguish ourselves from the media that support and nourish us. Close and ubiquitous, the medium is invisible; its properties become ours.
Common sight in a high school lab: a petri dish filled with agar medium and bacteria blooms.
In subsequent years, the sparks of McLuhan’s argument fanned out across academia, igniting fires that cleared entire forests of history and broad fields of study.
In the 1970s, after reading McLuhan, historian Elizabeth Eisenstein turned his insight on the Renaissance and Enlightenment, looking for evidence of movable type’s influence on intellectual, scientific and commercial life. The result was a series of papers, and in 1979, her mammoth tome The Printing Press as an Agent of Change, which attributes the demise of the Middle Ages to Gutenberg’s invention of the printing press in the 1440s.
Eisenstein mentions McLuhan four times in the book’s prologue and is clearly in his debt. “By making us more aware that both mind and society were affected by printing, McLuhan has performed, in my view at least, a most valuable service.” But Eisenstein condemns his approach as ahistorical. “He has also glossed over multiple interactions that offered under widely varying circumstances in a way that may discourage rather than encourage further study.” Likewise, some of Eisenstein’s generalizations have since been picked apart, but her thesis is still compelling. She implicates the printing press in revolutions in culture—religion, business, the arts, even self-consciousness—and the sciences, including botany, astronomy, anatomy, geography, physics, math and chemistry.
Even before Eisenstein, text book authors commonly recognized that the printing press had transformed Christianity in Europe, launching and propagating the Reformation. Martin Luther himself described printing as “God’s highest and extremest act of grace, whereby the business of the Gospel is driven forward.” Scholars have documented how Luther’s 95 Theses, after being nailed as a handwritten sheet on a church door in Wittenberg in October, 1517, were pushed by profit-hungry printers and book peddlers “throughout Germany in a fortnight and throughout Europe in a month.” Luther’s theses were themselves triggered by his disgust at the mass production of printed indulgences (featuring blanks to be filled by the buyer) being peddled (on commission!) to help fund the rebuilding of St. Peter’s Basilica in Rome. And the printing press freed Christians in Northern Europe to read for themselves mass-produced Bibles in their own languages, rather than depending on priests to read from a sometimes padlocked Latin manuscript.
But before Eisenstein, historians did not go further than though, giving the printing press just a line or two in their standard “other important factors” paragraphs about the dusk of the Middle Ages or the dawn of the Renaissance. Eisenstein, however, argued that print’s revolutionary effect went far beyond shattering the monopoly of medieval Catholic church and its scribes. What follows is a quick sketch of a few of her book’s herd of mammoth premises.
Capitalism: Printing was one of the first acts of commercial mass production, and, in cities and towns across Europe, printers were a new and dynamic class of entrepreneurs. They innovated constantly, seeking an edge on competitors by introducing concepts like title pages, paragraphs, and indexes. Printers both mass produced knowledge and marketed it, investing heavily in cultivating new tastes among book buyers.
Humanism: By unleashing a flood of mass market novels, memoirs, and romances, printers helped promote the individualism and humanism that are one of the Renaissance’s hallmarks. Indeed the concept of individual ownership of ideas, via copyright and patents, was conceived in Venice just a few years after the printing press arrived there. Absent the printing press, it’s unlikely that Montaigne, the ur essayist, would have written—and it’s certain we would not have read—”So, Reader, I am the subject of my book.”
Education: Boosting the cost-efficiency of book production by an estimated 300 X, the printing press created a reading public, people who weren’t nobles or churchmen, but could afford their own collection of books. To take just one fascinating example of this explosion of popular reading, within 50 years of Gutenberg’s innovation, self-help books were already among printers’ best selling genres.
Even a superficial observer of sixteenth-century literature cannot fail to be impressed by the ‘avalanche’ of treatises which were issued to explain, by a variety of ‘easy steps,’ (often supplemented by sharp edged diagrams) just ‘how to’ draw a picture, compose a madrigal, mix paints, bake clay, keep accounts, survey a field, handle all manner of tools and instruments, work mines, assay metals, move armies or obelisks, design buildings, bridges and machines.
Science: Eisenstein even argues that the printing press and its economic agents both enabled and popularized the concept of progress, a core concept underlying the Enlightenment. Between the fall of the Roman Empire and the middle of the 15th century, the production of books in Europe was devoted almost entirely to preserving, through reproduction, the wisdom of the ancients. “Just as scribal scholars had all they could do to emend Saint Jerome’s version and to protect it from further corruption, so too did medieval astronomers labor to preserve and emend Ptolemy’s Great Composition.” The burning of the Library of Alexandria in 48 CE haunted scholars and scribes, who struggled to find “lost books” on shelves in villas and monasteries across Europe and reproduce them through manual copying.
Unfortunately, the scribal practice of saving books was imperfect. Manual copying resembled a game of telephone; each successive copy introduced errors and mutations, which were in turn amplified by subsequent copyists.
When precise reproductions made with movable type replaced error-prone copies, three things happened.
First, the market was quickly flooded with competing versions of previously scarce ancient texts. Their reproduction became less urgent for scholars; public demand for ancient texts was gradually satiated; printers, eager to continue to make money, moved on mining to new topics.
Second, mass produced editions of books allowed scientists to create a shared language that facilitated progress. “The development of neutral pictorial and mathematical vocabularies made possible a large-scale pooling of talents for analyzing data, and led to the eventual achievement of a consensus that cut across all the old frontiers.”
Finally, and most importantly, knowledge production became iterative and cumulative. “The advantages of issuing identical images bearing identical labels to scattered observers who could feed back information to publishes enabled astronomers, geographers, botanists and zoologists to expand data pools far beyond previous limits.” Printed maps could be carried on voyages, annotated, and then returned to home port to improve the original template. Bound in affordable, portable copies, copper-plate reproductions of anatomy and botany images were compared to nature and precisely improved; in the 150 years after Gutenberg’s invention, the number of plants described in botany books blossomed from 600 to 6,000.
History: Classical thinkers believed time was cyclical. Medieval theologians believed they lived in end times. In either cases, with he act of book production largely confined to salvaging and reproducing ancient texts, libraries were frozen in time. Then, in a generation, time’s arrow started to move forward. As the printing press facilitated the accumulation of knowledge, it became clear that a new era, a better era, had begun. “The closed sphere or single corpus, passed down from generation to generation, was replaced by an open-ended investigatory process pressing against ever advancing frontiers,” writes Eisenstein. Time became linear. Eisenstein argued, in subsequent essays, that the idea of progress itself, the Enlightenment’s battle cry, was invented by book sellers as an promotional tagline attached to new books to distinguish their wares from what was already on the market. Their equation of newer and better has echoed for 500 years.
In 1985, NYU professor Neil Postman published Amusing Ourselves to Death, turning McLuhan’s lens on to politics, religion and education in the United States.
The book argues that the United States has been transformed by a transition from pervasive print-based communications to communication dominated by telegraph, radio and TV. The transition was as invisible as it was immense. “Introduce the alphabet to a culture and you change its cognitive habits, its social relations, its notions of community, history and religion. Introduce the printing press with movable type, and you do the same. Introduce speed-of-light transmission of images and you make a cultural revolution. Without a vote. Without polemics. Without guerrilla resistance.”
As summarized by book reviewers, Postman’s book is an indictment of television culture versus print culture. “Under the governance of the printing press, discourse in America was generally coherent, serious and rational… under the governance of television is has become shriveled and absurd.” Print extrudes discourse into linear thought and logical argument; electronic media reduces complex ideas to soundbites, impressions and identity-celebrations.
Reviewers summarized Postman’s book as a withering critique of television’s dumbing-down of culture. But the book makes a more profound argument, that the United States of America was created in and of print. Postman presents nuanced arguments and concrete evidence that “America was as dominated by the printed word and an oratory based on the printed word as any society we know of.” While European nation-states gradually and continuously evolved, usually without recourse to printed books or newspapers, from inchoate populations into distinct political and geographic entities, public life in the colonies was, from day one, conveyed and structured by print.
Unlike Europe, America started with a clean page, and its new life was printed onto that page. Print both educated Americans and bound this people, strewn across a giant wilderness, together through media like newspapers, post offices and libraries. In 1770, a New York newspaper wrote:
'Tis truth (with deference to the college) Newspapers are the spring of knowledge, The general source throughout the nation, Of every modern Conversation.
Postman doesn’t just believe that print was pervasive, but that it molded the American mind. “Public business was channeled into and expressed through print, which became the model, the metaphor and the measure of all discourse.”
Like a younger sister eager to show-up to elder siblings, Americans were intellectual overachievers. Literacy was markedly higher in the US than in Europe. More than 24 million copies of Noah Webster’s American Spelling Book sold between 1783 and 1843, a period in which the US population grew from 2.7 million to 17 million. “The poorest labourer on the shore of the Delaware thinks himself entitled to deliver his sentiment in matters of religion or politics with as much freedom as the gentleman or the scholar… Such is the taste for books of every kind that almost every man is a reader,” one commentator wrote in 1772.
Just as Eisenstein argues that the printing press birthed the Enlightenment, Postman suggests the printing press formed the USA. Producing, distributing and promoting print materials was a cornerstone American industry. Benjamin Franklin is just one of many printers who played a key role in the American Revolution.
Alexis de Tocqueville, after visiting the US in 1831, noted that even backwoods Americans were formed and informed by print. A typical pioneer might look “primitive and unformed,” but “he is acquainted with the past, curious of the future, and ready for argument upon the present; he is, in short, a highly civilized being, who consents, for a time, to inhabit the backwoods, and who penetrates into the wilds of the New World with the Bible, an axe, and a file of newspapers.”
Postman uses the debates between Abraham Lincoln and Stephen A. Douglas to cleverly illustrate how different minds were in the 1850s versus today. To hear the debates, thousands of men and women would travel for hours to stand in the sun and listen to speeches that might cumulatively stretch seven hours. Lincoln and Douglas typically spoke in 60 to 90 minutes blocks full of complex sentences and multi-part arguments. Their spoken language was, in Postman’s pithy summary, “pure print,” and their audiences were fully accustomed to attentive digesting it.
This print craziness obviously wasn’t just confined to politics. Dickens and Twain toured lecture halls in towns and cities across the country, drawing massive audiences. Summing up, Postman notes that “the printed word had a monopoly on both attention and intellect, there being no other means, besides the oral tradition, to have access to public knowledge.”
If culture dominated by print was “characterized by a coherent, orderly arrangement of a facts and ideas,” the advent of the telegraph in the 1830s and 1840s sowed the seeds of the sound bite and brought hints of a hurricane of trivial news. For a contemporary’s view of this transition, Postman quotes Thoreau in Walden, “We are eager to tunnel under the Atlantic and bring the old world some weeks nearer to the new; but perchance the first news that will leak through into the broad flapping American ear will be that Princess Adelaide has the whooping cough.”
“The principal strength of the telegraph was its capacity to move information, not collect it, explain it or analyze it,” argues Postman. Now American discourse was marked by irrelevance (information was valued for its novelty), impotence (information about remote topics beyond the reader’s reach), and incoherence (facts emerging so quickly that no narrative through-lines could be constructed.)
The telegraph launched the Age of Show Business, which, decades later, television only magnified. “The single most important fact about television is that people watch it… and what they watch, and like to watch, are moving pictures—millions of them, of short duration and dynamic variety. It is in the nature of the medium that it must suppress the content of ideas in order to accommodate the requirements of visual interest; that is to say, to accommodated the values of show business.”
Television, cramming together minutes of absurdist cuts from comedy to tragedy, creates “a discourse that abandons logic, reason, sequence and rules of contradiction.” We are fed “information that creates the illusion of knowing something but which in fact leads away from knowing.” This is important because “television is our culture’s principal mode of knowing about itself.”
“It does everything possible to encourage us to watch continuously. But what we watch is a medium which presents information in a form that renders it simplistic, nonsubstantitve, nonhistorical and noncontexttual; that is to say, information packaged as entertainment.”
Television pulled other communication modes into it slipstream, argues Postman. USA Today, launched in 1982, quickly became a nationwide best seller peddling nothing but short articles and lots of photos. The paper’s editor-in-chief declared he wasn’t chasing Pulitzers—”they don’t give awards for best investigative paragraph.”
Postman examines how television had reshaped education and religion in its image, but his strongest (and in retrospect, most disturbingly prescient) analysis applies to US politics.
As television ads eventually became the chief vessel for conveying US politics, politics, like a cake falling from its mold, has taken on advertising’s shape. “Today, on television commercials, propositions are as scarce as unattractive people. The truth or falsity of an advertiser’s claim is simply not an issue.” TV ads are not about the character of the products but the character of the consumer. “The commercial asks us to believe that all problems are solvable, that they are solvable fast, and that they are solvable fast through the interventions of technology, techniques and chemistry.”
Most of us “vote our interests, but they are largely symbolic ones, which is to say of a psychological nature. Like television commercials, image politics is a form of therapy, which is why so much of it is charm, good looks, celebrity and personal disclosure.”
Read in the 1980s, Postman might have come off as an alarmist or an elitist crank. Read in 2020, in a nation led by a former reality TV star famous for dating ex-Soviet models, bankrupting casinos, and shouting “you’re fired,” Postman is Nostradamus.
With all this in mind, it seems well past time to focus McLuhan’s lens on the making of American medicine. Considered in terms of periods of ascendant media, the history of US medicine breaks into (at least) five sometimes overlapping eras.
1700-1900
In the 18th and 19th centuries, Americans frequented medicine shows for both amusement and health remedies. The horse-drawn entertainers travelled muddy paths between homesteads and villages to sell each proprietor’s own hand-mixed nostrums. (Before launching his eponymous circus, PT Barnum floundered for a few years as a medicine pitchman. He traversed New England peddling Proler’s Bear Grease— guaranteed to grow hair!—from a gaudy wagon.)
When not buying from travelling hucksters, most people relied on home remedies—concoctions literally made and consumed in the home. According to Paul Starr’s history of American medicine, Scotsman William Buchan’s book Domestic Medicine was a favorite resource, going through at least 30 editions. Buchan’s book emphasized diet and simple preventative measures—exercise, fresh air, cleanliness. Buchan was avowedly populist. In his discussion of smallpox vaccination, Buchan argued that doctors often retarded medical progress. In his words, “the fears, the jealousies, the prejudices, and the opposite interests of the faculty [elite physicians] are, and ever will be, the most effectual obstacles to the progress of any salutary discovery.” Doctors should be consulted only in extremis, argued Buchan.
Doctors came in many stripes, as Starr documents. After early attempts, state by state, to institute medical licensure at the beginning of the 19th century, a wave of Jacksonian populism wiped away formal accreditation in most states. Anyone could practice medicine. For aspiring doctors, both medical societies and medical schools offered means of establishing credibility with patients. Competing with each other for fees, the two institutions lowered standards and boosted the supply of doctors; diplomas and certifications abounded. Many doctors had second careers. Farming was a popular second job; one doctor moonlighted robbing stagecoaches.
1850-1900
Since the founding of the Republic, the US has subsidized postal rates for publishers. As the US Postal Service notes, George Washington regarded magazines and gazettes to be “easy vehicles of knowledge, more happily calculated than any other, to preserve the liberty, stimulate the industry and meliorate the morals of an enlightened and free People.” Postal rates were slashed 50% in 1851 in part to counter the doubling of the price of rags that went into paper. And, in the late 1860s, the adoption of cheap wood pulp as newsprint (versus the previous rag-based paper) initiated a epic publishing boom. The new newspapers, gazettes, magazines and almanacs were filled by ads for “patent medicines,” which accounted for one third to one half of all ads in US newspapers in the nineteenth century. As one chronicle of the era puts it, “Newspapers made the patent medicine business, which in turn supported the newspapers.” Patent medicines were often national brands, mass produced, transported by rail, and paid for by mail order. “Prescriptions” were often form letters—with each buyer’s name and sex inked in for added veracity—mailed out by patent medicine firms.
(Later, many of these patent medicine brands shed their medicinal claims and, with deep-set commercial foundations, remain familiar today, most notably Coca Cola, which was originally peddled as an intelligence booster, and Pepsi. And while Pharma today showcases drug companies’ scientific and humanitarian roots, some prominent companies got their start hawking patent medicine. For example, Eli Lilly’s first blockbuster was Succus Alteran, a treatment for venereal disease, rheumatism, and psoriasis; it was “produced from a secret formula, purportedly derived from Creek Indians.”)
Doctoring was still hit or miss. Though microbes were identified as a source of disease illness in 1870, most infections remained untreatable until the advent of antibiotics in the 1940s. New instruments like the stethoscope, ophthalmoscope, spirometer, electrocardiogram and laryngoscope added “added a highly persuasive rhetoric to the authority of medicine,” but did little to prolong life. Most health gains in the period resulted from advances in public health—plumbing, sewers, nutrition, rising incomes, water purification—rather than interventions by individual doctors.
1900-1920
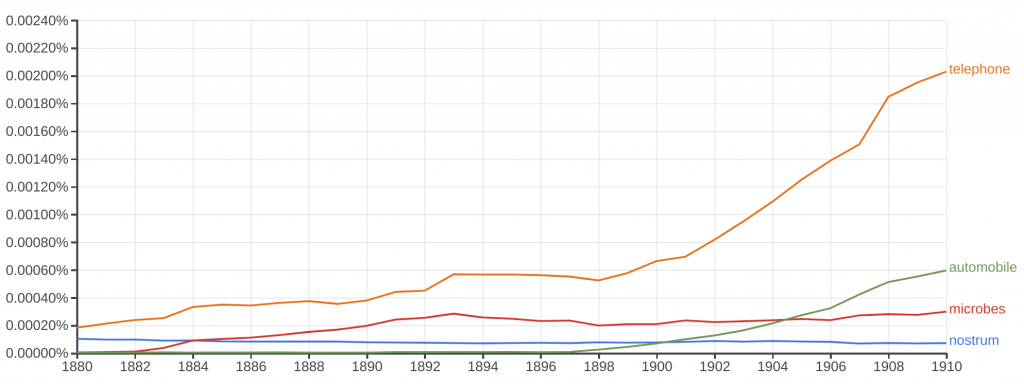
At the turn of the 20th century, doctors were among the first to adopt telephones and cars, which made doctoring far more efficient and lucrative. (Google graph of word frequency in a cross section of scanned books.)
Before 1900, “many people thought of medicine as an inferior profession, or at least a career with inferior prospects,” according to Starr. The average American doctor earned less than “an ordinary mechanic,” riding miles each day on horseback to see just a handful of patients.
The status of doctors changed dramatically in the first decade of the 20th century, when cars, telephones and urbanization—all media in McLuhan’s rubric—made the practice of medicine more efficient and, in turn, more lucrative.
Some nuggets that help make these changes more tangible:
Starr reports that “the first rudimentary telephone exchange on record, built in 1877, connected the Capital Avenue Drugstore in Hartford Ct, with twenty one local doctors.” Drugstores had long functioned as message boards for physicians, and many patients, still phoneless, visited a drugstore to connect with a doctor.
Doctors were early adopters of automobiles, writes Starr. The Journal of the American Medical Association published several auto supplements between 1906 and 1912. Doctors reported that, compared with a horse, house calls using a car took half as much time and were 60% cheaper. (In Arrowsmith, Sinclair Lewis’ satire of medicine, the eponymous protagonist’s best friend leaves med school in 1908 to sell cars, and a med school professor advises students that patients’ tonsils are essentially a currency for acquiring a luxury automobile.)
The US population living in a settlements of more than 2500 rose from less than 30% in 1880 to 45% in 1910, notes Starr. In the northeast, population density in settlements soared from 200 people per square mile in 1890 to 450 in 1910. Concentrating patients made doctoring cheaper. In addition to density, cities pooled single people lacking family support, which helped spawn hospitals, argues Starr. And, in turn, hospitals facilitated specialization, capital investment and knowledge sharing. Hospitals also bolstered the authority of local medical associations, since these groups often dictated which doctors could admit patients to hospitals.
These factors, cumulatively, transformed the practice of doctoring. At the turn of the century, many doctors’ incomes doubled, and their social status and political clout climbed accordingly. In step with unionization in other trades in the period, doctors reorganized and strengthened the American Medical Association; its membership rose from 8,000 in 1900 to 70,000 in 1910, writes Starr. Doctors used their new clout to limit competition—halving the number of medical schools, marginalizing non-accredited healers, and lobbying to end direct-to-consumer advertising by patent medicine makers.
Doctors were frequently quoted in Samuel Adam’s famous 1905-1906 series about patent medicines, The Great American Fraud, in Colliers Weekly. The opening paragraph marked the beginning of the end of patent medicines:
Gullible America will spend this year some seventy-five millions of dollars in the purchase of patent medicines. In consideration of this sum it will swallow huge quantities of alcohol, an appalling amount of opiates and narcotics, a wide assortment of varied drugs ranging from powerful and dangerous heart depressants to insidious liver stimulants; and, far in excess of all other ingredients, undiluted fraud. For fraud, exploited by the skillfulest of advertising bunco men, is the basis of the trade. Should the newspapers, the magazines and the medical journals refuse their pages to this class of advertisements, the patent-medicine business in five years would be as scandalously historic as the South Sea Bubble, and the nation would be the richer not only in lives and money, but in drunkards and drug-fiends saved.
The AMA, in turn, converted the series into a pamphlet, printing and distributing 500,000 copies. (Some newspapers, dependent on patent medicine ads, later refused to run ads for books by Adams.) Public outcry and AMA lobbying led to passage of the Pure Food and Drug Act of 1906, which strengthened the role of the Bureau of Chemistry, precursor of the FDA, in policing claims by drug makers.
1920-2000
Thanks to crusading journalists and lobbying doctors, drug makers’ access to consumers through ads was increasingly throttled as the 20th century progressed. In response, manufacturers focused on cultivating doctors as lucrative allies in flogging drugs. Over the last 100 years, drug makers have perfected a number of methods.
At the simplest level, drug companies promote their wares to doctors by advertising in medical journals.
They also, today, pay an army of an estimated 100,000 salespeople to talk with doctors. Drug companies track doctors’ prescription habits using a databased licensed, in part, from the AMA. Using extensive notes and “finely titrated doses of friendship,” the salesforce targets physicians with meals, flattery, honoraria, free samples, sports tickets, drinks, business consulting, support for favorite little league teams, and sundry other gifts. Physicians are susceptible to influence, says one former sales rep, “because they are overworked, overwhelmed with information and paperwork, and feel under appreciated.” Conveniently for the drug companies, physicians believe themselves to be righteously impervious to influence, despite abundantevidence to the contrary. Perversely, one Canadian study found that “the more gifts a doctor takes, the more likely that doctor is to believe that the gifts have had no effect.”
Then there are the spokes-doctors (known as speakers) who are collectively paid billions each year, according to amazing data compiled by watchdog Propublica, to explain products to their credulous peers while being proctored by company sales reps. One doctor describes being called on the carpet after he deviated from the company-created Powerpoint deck. “The manager’s message couldn’t be clearer: I was being paid to enthusiastically endorse their drug. Once I stopped doing that, I was of little value to them, no matter how much ‘medical education’ I provided.”
The apogee of the power of the printing press to make medicine can be found in successive editions of the Diagnostic and Statistical Manual, known by both its fans and detractors as the Bible of American psychiatry. In the second half of the twentieth century, this diagnostic manual transformed how psychiatry was practiced by doctors, paid for by insurance companies, and understood by patients and potential patients.
Allen Frances, known at one time as the US’s most influential psychiatrists and a former chair of Duke’s department of psychiatry, played a senior role in the creation of DSM-III and DSM-III-R, and Frances led the creation of DSM-IV. But Frances ultimately concluded the DSMs were a fool’s errand, and his 2013 book Saving Normal chronicles their flawed agenda, mechanistic execution, and tragic effects.
Frances argues that psychiatry’s domination by the DSM and drug marketing is just “a special case” of a problem that’s pervasive across US medicine: “Commercial interests have hijacked the medical enterprise, putting profit before patients and creating a feeding frenzy of overdiagnosis, overtesting, and overtreatment.”
Even as researchers consistently failed for 50 years to find biological causes for unhappy or disordered minds, successive editions of the DSM triggered both diagnostic hyperinflation and a false enshrinement of its “useful constructs” as concrete diseases, Frances argues.
“Billions of research dollars have failed to produce convincing evidence that any mental disorder is a discrete disease entity with a unitary cause,” notes Frances. But, thanks to the DSM and aggressive drug company marketing, two generations of doctors and patients now casually believe that people “have” mental diseases. In contrast, Frances believes strongly that phenomena like schizophrenia and depression are (as he put it recently on Twitter) “just a construct- not something you can have.” No two patients are identical, and “the boundaries demarcating the different disorders are ever so much fuzzier in real life than they appear to be on paper.” The DSMs describe “only of what is most surface and common in mental disorders.”
Adapted by the American Psychiatric Association from a US Army manual, DSM-I (1952) and DSM-II (1968) were “unread, unloved and unused,” according to Frances. But two influential papers in the early ’70s—both demonstrating that psychiatric diagnoses were wildly inconsistent—raised the stakes for the drafters of DSM-III. If psychiatry were to remain credible, its professors and practitioners desperately needed to “end diagnostic anarchy” and shore up psychiatry’s claims to scientific rigor.
Convened in the mid 1970s, the committees of psychiatrists who created DSM-III believed that their work, focused on describing surface symptoms, was “atheoretical in regard to etiology [causes] and equally applicable to the biological, psychological and social models of treatment.” But this claim to neutrality was undercut by the reality that “the surface symptoms method fit very neatly with a biological, medical model of mental disorder and greatly promoted it.” Possible social and psychological causes for mental distress were essentially written out of the body of psychiatric knowledge by DSM-III. Why inquire into the “narrative arc” of a patient’s life when he or she could be understood by “filling out a checklist?”
DSM-III “truncated the field of psychiatry and triggered diagnostic inflation,” writes Frances. The book “was greatly oversold and overbought.”
McLuhan, if he were alive today, might argue that the DSMs embody the culmination of the Enlightenment project—launched, of course, by the printing press—to scientifically define, describe and control the human condition. The DSM’s mechanistic worldview is telegraphed by its title. “Diagnostic” promises scientific categorization based on biological features; “statistical” implies mathematical rigor; and a “manual” is a set of instructions for operating a machine. Psychiatric medications haven’t substantially improved since the 1950s, according to Frances, but the diagnostic manuals implied that psychiatry had insight into physical causes, which in turn suggested the likelihood of physical solutions. The DSM became a self-perpetuating mythology, an instrument of propaganda for the belief that mental disorders are biologically substantive, distinct, subject to diagnosis and responsive to pharmacological intervention.
While each additional category and subcategory carved into the succeeding DMSs theoretically represented a specification or subdivision of a previous category, the end result was a blurring and expansion of psychiatry’s empire. In Frances’ words, “splitting inherently leads to diagnostic inflation.”
Objectified in the DSMs, the act of diagnosis has transitioned from being a means to an end. Frances noted in a 2014 recap of his book that “doctors in the US usually don’t get paid for a visit unless they provide a reimbursable diagnosis for it. Doctors find it easy to give a diagnosis, but patients find it difficult ever to get rid of it- however inaccurate it may be.” The DSM’s diagnoses have been leveraged by drug companies in their advertising (more on this shortly); the DSM became a tool for prodding the “worried well” to, as many TV ads for drugs still intone, “ask your doctor” about a condition. The sale and licensing of the DSM became “a cash cow” for the American Psychiatric Association, which, according to Frances, treated the work “as a private publishing asset rather than a public trust.” And, to market its product, the APA relied on the conceit 16th century printers invented to peddle their own wares: get the latest edition, it’s new and improved!
The DSMs, Frances argues, reified “useful constructs” into “diseases,” a conceptual slight of hand that gave both psychiatrists and family doctors a false sense of scientific certainty. Far more people are hurt by psychotropics—as they’re current prescribed—than helped, Frances writes. DSMs set the stage for “huge epidemics of autism, ADHD and bipolar disorder,” according to Frances.
In his view, if a psychotropic treatment succeeds its probably because of the placebo effect; most unhappy or disordered minds currently being dosed with drugs after 15 minute appointments would be more effectively restored by empathy, the passage of time and the adoption of a positive self-narrative.
“New and improved” not withstanding, Frances notes that throughout the 50 year succession of DSM editions, science made no progress in the understanding of the biological origins of mental disorders. Pharma stopped making significant psychotropic discoveries long ago, laments Frances.
DSM in hand, Pharma marches on. In Frances words: “In recent decades, the drug companies have efficiently hijacked the medical enterprise by exerting undue influence on the decisions made by doctors, patients, scientists, journals, professional associations, consumer advocacy groups, pharmacists, insurance companies, politicians, bureaucrats, and administrators. And the best way to sell psychotropic pills is to sell psychiatric ills. Drug companies have many methods of doing this: TV and print media adverts; co-opting most physicians’ continuing medical education (often provided at the most expensive restaurants and at the nicest resorts; doctors in training and medical students come cheaper—a pizza will do); bankrolling professional associations, journals and consumer advocacy groups; invading the Internet and social networking sites; recruiting celebrity endorsements.”
“The seeds of diagnostic inflation that had been planted by DSM-III would soon become giant beanstalks when nourished by drug company marketing.”
1997-2020
In 1983, the FDA shut down an ibuprofen ad directed at consumers — an antique featuring the company’s suit-clad British CEO and a chalkboard — that aired briefly on TV. Over time, though, court rulings made it clear that drug makers’ First Amendment rights would be upheld if they challenged the FDA.
So, when the FDA changed its rules to allow drug companies to promote products directly to consumers in TV ads without including a detailed list of side-effects, medicine jibed in a new direction again in 1997.
Critics say drug companies increasingly divert from finding new treatments for illnesses towards “disease mongering”— finding and promoting new disorders, preferably chronic, that can be treated with previously FDA-approved drugs. Expensive “me-too” drugs, patented for a trivial improvement but heavily marketed, also soak up company resources. Companies like IQVIA ($27 billion valuation) mine data seeking new market niches for existing drugs. Shyness gets rebranded as “social anxiety disorder,” treatable with Paxil, a $3 billion/year antidepressant. In progressive revisions of psychiatry’s handbook, the Diagnostic and Statistical Manual, committees of researchers, most of whom are funded by drug companies, both loosened treatment criteria and ramped the number of the psychiatric disorders from 106 in edition 1 in 1952 to 297 in edition 5. Almost all those disorders lack biomarkers or diagnostic verifiability.
Gradually, the white-coated doctors who traditionally served as drug company CEOs have departed, their places taken by businessmen in suits. Today, just three doctors remain among the CEOs of the world’s biggest 15 drug companies; the rest are former sales reps (3), lawyers (2), economists (2); the rest are scattered across marketing, biz dev, operations, investment banking, and consulting. (One is a woman, one is African American.)
Frances, repentant Prospero of DSM-IV, describes how drug companies exploited diagnostic categories to expand the use of anti-psychotics from schizophrenia to bipolar disorder. “First, the drug companies had to get an indication for bipolar disordered and then they had to advertise a conception of bipolar disorder so broad as to be unrecognizable. Anti psychotics were soon being prescribed promiscuously, even by primary care physicians, to patients with garden variety anxiety, sleeplessness, and irritability. The paradox is that dangerous drugs capable of causing massive obesity, diabetes, heart disease, and a shortened life span now account for $18 billion a year in sales.”
Looking at broader trends in prescribing, Frances concludes, “we have become a pill popping society, and very often it is the wrong people who are popping the wrong pills as prescribed by the wrong doctors.” The outcome “approximates the quackish practice of medieval alchemists.”
"We are the primitives of a new culture." sculptor Umberto Boccioni in 1911, quoted in McLuhan's The Gutenberg Galaxy
Many health challenges have been overcome since 1900. Infant mortality is down 90% and maternal mortality is down 99%, according to the CDC. Vaccines have eliminated smallpox and polio, and slashed measles infections by 99.8%. Many cancers are now chronic conditions rather than death sentences. (Medicine’s triumphs notwithstanding, advances in public health are credited with 25 of the 30 year lengthening in US life spans between 1900 and 2000.)
The health challenges that remain are complex and, often, multivariate: Alzheimer’s, Parkinsons, arthritis, and psoriasis; conditions like Diabetes 2 and heart disease, whose etiology is sometimes behavioral; and orphan diseases, guerrilla fighters holed up out of sight of medicine’s regular brigades and firepower.
Beyond the obscurity, intractability or complexity of each lingering disorder or illness, the infrastructure of medicine itself has erected barriers to innovating and solving patients’ problems. McLuhan, no doubt, would recognize the 21st century industry of medicine itself as a rigid medium which predetermines inputs and outcomes.
Though its content has changed, the structure of medical training is fundamentally unchanged over the last 100 years. “At the time the architecture of medical education was defined a century ago, doctors largely worked independently of each other,” notes Clayton Christensen in Innovator’s Prescription, his 2016 book about US medicine. This leaves them untrained for the challenges of modern medicine, in which multiple specialized functions and people come to bear on a patient’s needs. Trained to “do” medicine, doctors aren’t prepared to think about how the system itself operates.
And while the functions performed by hospitals also have grown immensely more complex over the last 100 years, their organizational DNA is unchanged, argues professor Steven Spear of MIT. “Typically, care in a hospital is organized around functions. Issuing medication is the responsibility of a pharmacist, administering anesthesia of an anesthetist, and so on. The trouble is, that system often lacks reliable mechanisms for integrating the individual elements into the coherent whole required for safe, effective care. The result is ambiguity over exactly who is responsible for exactly what, when, and how. Eventually a breakdown occurs—the wrong drug is delivered or a patient is left unattended. Then, doctors and nurses improvise. They rush orders through for the right drugs, urge colleagues to find available room for patients, or hunt down critical test results. Unfortunately, once the immediate symptom is addressed, everyone moves on without analyzing and fixing what went wrong in the first place. Inevitably, the problem recurs, too often with fatal consequences.”
As one nurse put it to Spear, health care professionals confront “the same problem, every day, for years,” which results in inefficiencies, irritations and, sometimes, catastrophes.
Drug and device manufacturers focus on milking their past winners and funding potential blockbusters. The FDA’s rigorous clinical trial requirements make micro-experiments on treatments for orphan disorders risky and uneconomical.
Doctors are overworked and demoralized, stretched by demanding corporate bosses and electronic record keeping. The electronic medical record (EMR) software mandated in 2009 is, no surprise since you’re still reading this essay, reshaping medical care. Atul Gawande noted that “a system that promised to increase my mastery over my work has, instead, increased my work’s mastery over me.” More cynically, “EMRs no longer seem to even pretend to be about patient care,” writes Dr. Judy Stone. “The goal is to optimize billing through upcoding. You do that, in part, by ‘documenting’ more, through check boxes and screens that you can’t skip.”
Now another era is media dawning, that of patient driven medicine. Early in the 21st century, social media is leading to changes in medicine’s trajectory. Social media is empowering patients with niche medical conditions to network and pursue collective action; in parallel, powerful new targeted ad technology makes it possible for companies to target these patients’ needs. These communities range from disease-independent platforms like PatientsLikeMe to Facebook groups for people with migraines or psoriasis. Podcasts and communities run by Peter Attia and Rhonda Patrick are organizing new constituencies for longevity and athletic health. Millions of members of Strava, Peloton, Zwift and the Potterhead Run Club focus on community and healthy competition. Programmers share code on Github. Laypeople and pros trade insights at Twitter hashtags like #LCHF. (All this is apparently invisible to tech pundits like Kara Swisher, who recently summed up social media as “a chaos machine that ginned up a world of socially acceptable sadism.”)
Patient communities may provide a vehicle for evading the gridlock, pulling innovation through that previously needed to be pushed. With patients convening and advocating for themselves, perhaps doctors will be able to transition from being expedition leaders to being sherpas.
In some cases, these communities have helped fund research or performed the research themselves. For example, parents of eight children with a rare genetic disorder called NGLY1coalesced around a single blog post and rallied to coordinate knowledge sharing and research for their children. Parents of two of those patients noted in an article in Nature:
Until very recently, the fragmented distribution of patients across institutions hindered the discovery of new rare diseases. Clinicians working with a single, isolated patient could steadily eliminate known disorders but do little more. Families would seek clinicians with the longest history and largest clinic volume to increase their chances of finding a second case… This challenge can be circumvented by tools already created for and by the Internet and social media.
Nineteen months after the initial report by Need et al.,2 five viable approaches to treatment are under active consideration, thanks to relentless digging by afflicted families. One parent found a compound that seems to have measurably raised the quality of life in one NGLY1 child. Another parent read about a novel (but relevant) fluorescent assay and shared it with the NGLY1 team. The team had not heard about it, but it has become a fundamental tool in the functional analysis of NGLY1. One parent has formed and funded a multi-institutional network of researchers to tackle specific projects. The capabilities of parents and the social media are frequently underestimated; we are here to say: join us!
Online communities of sleep apnea sufferers provide a case study of how these two burgeoning media categories—social media and biosensors—will alter, for better or worse, medicine’s trajectory. (Sleep apnea is an nightly series of breathing interruptions in that disrupt sleep, elevate cortisol levels and cause headaches and daytime sleepiness. Doctors traditionally prescribe a CPAP, a machine that continuously pushes air into a patient’s nose or mouth, to reduce sleep apnea. Meanwhile, humans’ understanding of a CPAP’s actual efficacy remains iffy.)
One product of patient generated medicine is a profusion of products created by companies leveraging new channels to communicate with patients. Because apnea sufferers commune online and can be tracked with ad technologies, companies are targeting them with hundreds of new promotions and products.
As of November, 1, 2019 Somniflex is running 47 ads for its ‘mouth tape’ product.One company, Fisher Wallace, is even running ads soliciting investors.
Another harbinger of the new age lies in open source software built by and for apnea sufferers. In 2011 one apnea sufferer, Mark Watkins, started working on software called Sleepyhead to decode the data collected by a patient’s CPAP machine.
“As time progressed, I became increasingly disgusted at how the CPAP industry is using and abusing people, and it became apparent there was a serious need for a freely available, data focused, all-in-one CPAP analysis tool” — Mark Watkins, creator of SleepyHead software
By reverse-engineering the data locked up on various brands and models of CPAP machines, Watkins gave users a various views of their own data in charts and graphs.
Watkins’ code has been promoted and discussed in numerous social media communities that focused on apnea and CPAPs. More than 78,000 sufferers belong to forum called Apneaboard. On an average night, 2,000 members are posting or lurking. Other boards like CPAPtalk have tens of thousands of members. On Facebook, a group of 1,000 focuses on central sleep apnea, a rare apnea subset. Without these groups’ attention and cheering, it’s unlikely Watkins software would have thrived.
Users say they get far better insight from Sleepyhead than from their own doctors. And academics now rely on Watkins’ code to compare various brands of CPAP machines, brands which try to keep their data in walled gardens.
Ironically, members the CPAPtalk community, agitating for a more aggressive development path, ultimately launched an offshoot of Watkins’ code (technically a “fork”) called OSCAR, and Watkins abandoned his project in early 2019.
Form creates function. A new medium—whether movable type, medicine shows, the telegraph, telephones, medical associations, manuals or Facebook groups—determines which kinds of knowledge can be easily shared. Each medium nurtures new economic entities—whether printers, hucksters, medical associations or drug companies—who exploit the medium for profit. Each medium congregates and organizes people in a new configuration, an audience. Each new audience enables and shapes new expectations, inspires or demands new products. The cycle never ends.
And so, for better or worse, how information flows controls where medicine goes.
When entertainment and drug making were local, Americans depended on nostrums made at home or sold by horse-drawn medicine shows.
When railroads and newspapers transformed the creation and promotion of goods, Americans were inundated with patent medicines.
When doctors rose in status because of telephones, cars, urbanization and unionization, they gained a monopoly medical standards and on dispensing medicines.
When, in turn, drug manufacturers used research and medical journals as tools to sell to doctors, medicine was steered by what the companies chose to fund and promote.
When televised drug ads were unleashed, consumers were sold on new sub-ailments. When drug companies co-opted the process of drafting diagnostic manuals, diagnoses multiplied.
Now social media is ushering in a new age, one in which individual patients, rather than institutions, can drive innovation, or quackery, in directions they choose.
Postscript: additional new media categories to consider
Two other media, new in the 21st century, are worth considering. The first, bio monitors, turn human experiences into reams of new data; these are, in a sense, a new form of biography, which will undoubtedly transform our sense of what a human being is. The second, machine learning, resembles the indexes and libraries of old, helping us keep track of the masses of information being created daily.
Thanks to bio monitors, many people now have up-to-the-minute access to giant volumes of their own health data, with details that are far more specific than those accessed by the average family practitioner. Moore’s law is making technology, both hardware and software, exponentially cheaper, smaller and/or more powerful. Affordable tools include real time glucometers, wifi-enabled oximeters, cloud-synched heart monitors (for data ranging from heart rate to EKG to heart rate variability), motion detectors, speech tracking tools… and many more. (ElektraLabs catalogs 600+ medical-grade connected biomonitors.) A full genome decoding, which cost $2.7 billion in 2003, was on sale (on Facebook, of course) for $189 on Black Friday 2019. Software (like ours!) uses n-of-1 protocols to power personal tests of drug efficacy, deconstructing drug makers’ efforts to peddle “average effects.” Dr. Eric Topol, director of the Scripps Translational Science Institute, argues that increasing patient access to more data and more insights will end the information asymmetries that generate medicine’s deep seated “extreme paternalism.” He argues that “just as Gutenberg democratized reading, so there is a chance that smartphones will democratize medicine.”
Machine learning is the only tool capable of processing the mind-boggling volume of data being generated by and about humans. Machine learning can trawl through billions of data points and detect patterns far subtler than anything human computation or senses might notice. The acceleration of machine is powered, in part, by Moore’s law: one vital computing resource for machine learning is doubling every 3 months. But the growth of machine is also founded on new theories and algorithms. As we shall see, machine learning threatens not only the doctor’s preeminence as the high priests of human health, but potentially destabilizes the conception of knowledge underlying the modern idea of progress.
As humans frantically write software to graph and analyze the data pouring out of biomonitors and demanded by specific communities, whether of athletes or sufferers of orphan diseases, we’re also seeing comprehensive attempts at digest data using machine learning. While machine learning (also called deep learning or neural nets or, more generically, artificial intelligence) sounds like just a new flavor of software, it is radically different. It’s theory-agnostic, approaching data with no hypotheses or assumptions or models in hand. It plows through oceans of data and fishes up patterns, insights, anomalies. It offers no theories about what it’s found.
In his recent book Everyday Chaos, technologist and philosopher David Weinberger suggests that “the rise of machine learning is one of the significant disruptions in our history.”
Each of us experiences a version of this phenomena every day. Google’s tens of thousands of engineers are famous for designing competition-thrashing algorithms to serve up useful information in response to people’s searches. In 1999, Google’s solution was a single simple rule—using the number of inbound links to a web page as a proxy for that page’s authority. Eventually, Google’s engineers wrote software that factored in hundreds of signals to help make this judgement. But a funny thing happened in 2015. Seeking to optimize its responses to searches it had never seen before — apparently 15% of Google searches are unique?!— Google did some testing and determined that machine learning, named RankBrain, did a better job than most of its massive, intricate, traditional human-built rules, to the dismay of some of its engineers. Google now leans on RankBrain when responding to unique searches. This means the managers of the world’s most influential processor of human information can’t explain the black box that powers 15% of its interactions with humans.
As Weinberger notes, choosing to rely on machine learning yields a radically different view of the universe in comparison to the positivist/progressive assumptions that guided the last 300 years of science and medicine. We’ve believed that rationality and experimentation carry us steadily forward into a better world. Humans will figure things out. This optimism is dogma in US medicine.
But this view is breaking down. “As our predictions in multiple fields get better by being able to include more data and track more interrelationships, we’re coming to realize that even systems ruled by relatively simple laws can be so complex that they’re subject to… cascades and to other sorts of causal weirdness,” writes Weinberger.
Confronting the fact that machine learning often produces insights and connections we can’t explain, “we’re beginning to accept that the true complexity of the world far outstrips the laws and models we devise to explain it,” We’re “losing our naive confidence that we can understand how things happen.”
This view is profoundly disruptive to both the theory and practice of medicine. Doctors rely on models and hypotheses to operate; their long-trained capacity to explain, even when they’re unable to cure, shores up their social authority. Now doctors being bettered by machines that invoke no models or hypotheses to do their work, and offer no explanations for their findings.
Physicians’ egos aside, the new paradigm has practical ramifications. In light of the fact that thousands of variables may affect a condition, napalming the tangled jungle of a particular disorder with one or even one dozen chemicals will soon be seen as vast overkill, both ineffective and a waste of resources.
Historically, doctors have fought change—whether the advent of the stethoscope or professional nursing or home pregnancy tests—that threatened to dilute their authority. It remains to be seen how doctors will relate to machine learning. When I mentioned Aging.ai to my own doctor, he was unfamiliar with the site. I explained that its neural net had processed hundreds of thousands of anonymized blood tests and found that a high BUN score is the single best predictor of early death. (This metric is of particular interest to me because my BUN is high, on par with an average 95-year-old’s.) He scoffed, “Ah, don’t worry about it, that’s just software.”
New developments since this was posted.
Daniel Quintana, a scientist at the University of Olso, has published an ebook about Twitter and science. Here is how he sums up the importance of social media for science: “Fortunately, social media has toppled the academic monopoly of attention that was once hoarded by a selective group of journals and conferences. Everyone now has a more equitable opportunity to get attention for their research.”
An n-of-1 trial is a experiment conducted for a single person in which treatment blocks are randomly rotated, symptoms are systematically logged, and results are statistically analyzed. Since many treatments work differently for different individuals, n-of-1 trials help determine a treatment’s efficacy for a specific individual. N-of-1 trials are typically used for chronic conditions and are not considered appropriate for acute illnesses.
Examplesof n-of-1 trails
October 2019: A unblinded study of ~200 patients with chronic pain showed that patients using an n-of-1 protocol used significantly less pain medication. The study allowed the n-of-1 users to objectively compare the efficacy of medications, both NSAIDs and opioids, versus non-pharmaceutical interventions like yoga and physical therapy.
In addition to being a term of art of evaluating common treatments for their efficacy on a single individual (as above) “n-of-1” is increasingly used in describing drug or genomic solutions crafted to fit a single patient’s needs. A good example of this is the recent case of Mila, a 6-year-old with a rare fatal genetic condition, was cured by doctors who crafted a drug specific to her genetic mutation.
No social media for 30 days, which was ‘easier than expected.’ Result: after the month was over, Peck discovered her phone was her addiction enabler.
Allowed social sites on the computer in the afternoons only — not in the mornings, or after dinner. Result: “I got so much more done on my biggest projects by having dedicated focus hours, and also knowing that there was a scheduled break in my day coming up.”
Created a “happy hour” in which she was free to browse. Result: “Strangely, consolidating all of my social media use into a single hour made it seem less exciting.”
Avoid social media (and the phone!) every Saturday. Result: “A day free of the Internet is a great way to do a pattern reset if you notice (as I have) personal productivity dips by Friday.”
In the end, Peck concluded that each approach had its merits and that ANY consciousness of social media addiction led to greater productivity and satisfaction.
Peck’s takeaway: “These experiments helped me realize that at the heart of my cravings around the social internet are deep connections with friends, access to new ideas and information, or time to zone out and relax after a hard day. Each of these components can be satisfied with other things beyond social media, and more effectively.”
The disconnect between the price trajectories of healthcare versus consumer electronics — the first doubling every 10 years, the second halving every three years — is one of the most glaring of the 21st century.
In coming months, that gap will start to close for people with hearing loss, as FDA-approved over-the-counter hearing aids appear on the market.
Traditional hearing aids cost up to $3,000 a piece. They’ve required a prescription, plus an audiologist’s fitting and tuning, yet were not covered by most insurance plans or Medicare. Of an estimated 30-40 million Americans with hearing loss, fewer than 1 in 4 have hearing aids. (Source.)
While the trade group for hearing aid manufacturers (portentously hosted at hearing.org!) lobbied for OTC hearing aids to be limited to people with mild hearing loss, the legislation included people with moderate hearing loss.
Currently you can buy a “personal sound amplification product,” known as a PSAP, in a pharmacy, but quality varies greatly. A study in 2017 found that for people with hearing loss, a prescription device boosted comprehension from 75% of words to 88%. Four of five PSAPs tested boosted comprehension to 81.4% to 87.4%. (One did worse than nothing!)
The process began in 2017, when the FDA Reauthorization Act of 2017 passed Congress and was signed into law. The act instructed the FDA to permit OTC hearing aids by 2019.
Meanwhile, stripped of their role as gatekeepers to hearing aids, audiologists are scrambling to reposition themselves. “Dependence on the audiogram is old-school and leads to a one-size-fit-all approach to hearing care,” wrote Weinstein, Barbara, a professor of audiology, in a trade publication for audiologists. “And with the passage into law of Section 709 of the FDA Reauthorization Act of 2017 (FDARA) that includes the Over-the-Counter (OTC) Hearing Aid Act, we must abandon this way of thinking. A maturing of our philosophy as audiologists should emerge from the disruptions presented by the FDARA, with an emphasis on the value added of engaging with audiologists.”
Critics argue that the “tuning” currently touted by audiologists is an artifact of a pre-digital age. “It’s true that we don’t go in and individualize each one, but [professional fitting] is an ancient byproduct of a time 30 years ago when [hearing aids] really needed to be tuned,” Christian Gormsen, CEO of Eargo, which makes hearing aids and sells them directly to consumers, told WebMD.
For now the only quality standard for OTC hearing aids will be the FDA’s, meaning manufacturers will strive to be “good enough” and probably compete only on price and aesthetics. If Underwriters Labs ever introduced testing and benchmarking for consumer medical devices (oximeters, hearing aids, heart rate monitors, sleep monitors), we might see companies put more effort into achieving objective excellence on metrics and utilities beyond size and design.
Though the effectiveness of many treatments varies widely across individuals, treatments are rarely rigorously evaluated on a personal basis. Instead, pressed for time, physicians rely on trial and error testing. But protocols for personal experiments are simple, and their benefits are well documented.
“We spend so much effort on precision in diagnosis, yet we have very little precision about treatment,” observed Dr. Eric Larson, a professor of medicine at the University of Washington.
Experts say that, even for widely-studied drugs, “the trial and error approach to medicine is not cost efficient because several of the most prominent drugs only work on one-third to one-half of patients. Thus, many patients are subjected to the cost, inconvenience, side effects, and potential adverse reactions of taking medicine that will have little to no clinical benefit.”
Responding to this problem in the late 1980s, medical researchers at McMaster University in Canada determined that many treatments for chronic conditions could be successfully evaluated on a person-by-person basis. (You can read a great history of that work here.) They advocated applying routine research techniques — standardized reporting, randomized treatment blocks, blinding, placebos and statistical rigor — to individual testing.
For chronic conditions, single patient trials are “not only ethical but arguably obligatory to undertake,” one researcher argued in 2002.
Though clearly needed, single person experiments are still relatively underutilized. “The apparent simplicity of this study design has caused it to be enthusiastically touted in some research fields and yet overlooked, underutilized, misunderstood, or erroneously implemented in other fields, ” note Jean Slutsky and Scott R. Smith of the US Agency for Healthcare Research and Quality.
The agency’s user guide to personal experiments, published in 2014, is an invaluable resource best practices in single person experiments.
The user guide defines n-of-1 trials simply as “multiple crossover trials, usually randomized and often blinded, conducted in a single patient.” Best practices include:
“Treatments to be assessed in n-of-1 trials should have relatively rapid onset and washout (i.e., few lasting carryover effects).”
“Regimens requiring complex dose titration (e.g., loop diuretics in patients with comorbid congestive heart failure and chronic kidney disease) are not well suited for n-of-1 trials.”
Blinding with the help of a compounding pharmacist or trusted friend can reduce placebo effects. Unfortunately, “even for drug trials, few community practitioners have access to a compounding pharmacy that can safely and securely prepare medications to be compared in matching capsules.”
“One-time exposure to AB or BA offers limited protection against other forms of systematic error (particularly maturation and time-by-treatment interactions) and virtually no protection against random error. To defend against random error (the possibility that outcomes are affected by unmeasured, extraneous factors such as diet, social interactions, physical activity, stress, and the tendency of symptoms to wax and wane over time), the treatment sequences need to be repeated (ABAB, ABBA, ABABAB, ABBAABBA, etc.).
“For practical purposes, washout periods may not be necessary when treatment effects (e.g., therapeutic half-lives) are short relative to the length of the treatment periods. Since treatment half-lives are often not well characterized and vary among individuals, the safest course may be to choose treatment lengths long enough to accommodate patients with longer than average treatment half-lives and to take frequent (e.g., daily) outcome measurements.”
“In n-of-1 trials, systematic assessment of outcomes may well be the single most important design element. … In the systematic review by Gabler et al., approximately half of the trials reported using a t-test or other simple statistical criterion (44%), while 52 percent reported using a visual/graphical comparison alone. Of the 60 trials (56%) reporting on more than one individual, 26 trials (43%) reported on a pooled analysis. Of these, 23 percent used Bayesian methodology, while the rest used frequentist approaches to combining the data.”
As noted above, the benefits of n-of-1 trials include reducing the cost, inconvenience, side effects, and potential adverse reactions of taking medicine that has little to no clinical benefit. A protocol counters the influence of numerous biases and errors. In studies of n-of-1 trials for some chronic conditions, a personal treatment experiment resulted in a treatment change for up to two thirds of individuals.
The most important result, though, may be increasing the participants’ sense of playing an important role in their own treatment journey.
To learn more about creating your own n-of-1 test for your own symptoms, engage with the GuideBot below!
Because many treatments’ effects vary depending on the individual, researchers argue that effectiveness should be evaluated per patient. Yet the simple evaluation method that’s been tested and refined for 30 years, called an n-of-1 trial, is rarely used. Why?
Most top selling US drugs for chronic conditions offer above average relief for only a fraction of treated patients. So, for nearly 30 years, researchers have advocated single patient treatment experiments, also known as an n-of-1 trials.
An n-of-1 trial uses standard scientific methodology—including placebos, blinding, random block rotation, crossovers, washouts and statistical analysis—to determine a drug’s efficacy for an individual patient. Their rigor and specificity mean that n-of-1 trials “facilitate finely graded individualized care, enhance therapeutic precision, improve patient outcomes, and reduce costs,” according to a 2013 review of 2,154 single patient trials.
To date, though, we’ve seen a failure of all attempts to provide off-the-shelf n-of-1 services that the average doctor might use for a patient.
“We spend so much effort on precision in diagnosis, yet we have very little precision about treatment,” says Eric Larson, Executive Director and Senior Investigator, Kaiser Permanente Washington Health Research Institute.
1) The average physician’s toolbox doesn’t include the necessary statistical hammers and nails to do a meaningful analysis. “In clinical practice, physicians use evidence and experience to generate a list of treatment options. Patients and physicians move down the list based on trial and error.”
2) N-of-1 trials require physicians to squeeze another process and script into their already-packed days. “Clinicians must explain the idea to their patients, see them regularly throughout the trial, and evaluate the results jointly at the trial’s end. … Taking the time to sell an unfamiliar concept—let alone follow through on the logistics—might be untenable.”
(A 2017 history of n-of-1 trials offers a more prosaic take: “‘did the treatment help?’ is too easy, and has too much face validity, compared to the more onerous substitution of a formal N of 1 trial.”)
3) Beyond the pragmatic challenges, N-of-1 trials force physicians out of their “cure-dispenser” role, the study noted. “While clinicians understand that the practice of medicine involves uncertainty, they are not necessarily comfortable with it. Recommending that a patient enroll in an n-of-1 trial acknowledges this uncertainty, suggesting that the physician does not really know what is best. It is much easier—and arouses far less cognitive dissonance—to simply write a prescription.”
As Gordon Guyatt, who pioneered research at McMaster University demonstrating the empirical superiority of N-of-1 trails, explains resistance to the n-of-1 innovation: “[Physicians] tend to have ways that they’ve learned to operate where they’re comfortable, and it’s hard to move outside these ways. It’s hard to do something extra that’s going to take time, and energy, and initiative.”
“Number Needed to Treat” for one patient to benefit, illustrated for the top ten drugs in the US. Source.
Some argue N-of-1 trials are long overdue. “Every day, millions of people are taking medications that will not help them,” argues Nicholas J. Schork, director of human biology at the J. Craig Venter Institute in La Jolla, California, USA. “The top ten highest-grossing drugs in the United States help between 1 in 25 and 1 in 4 of the people who take them (see chart below.) For some drugs, such as statins — routinely used to lower cholesterol — as few as 1 in 50 may benefit. There are even drugs that are harmful to certain ethnic groups because of the bias towards white Western participants in classical clinical trials.” Schork believes the time is ripe for n-of-1 trials. “Physicians are having to become more acutely aware of the unique circumstance of each patient — something most people have long called for.”
To learn more about creating your own n-of-1 test for your own symptoms, engage with the GuideBot below!